Documentation
Agentic Retrieval
This step lets the LLM decide which tools to execute and how often. This means, you can configure and label subsequent “tools”, i.e. pipeline sub processes, which allows the LLM to solve the task by the given prompt.
This mode has the advantage that collected knowledge is reused and does not get lost. But it consumes potentially more LLM tokens than the execution of other pipeline steps as each further iteration sends the entire context to the LLM.
Configuration
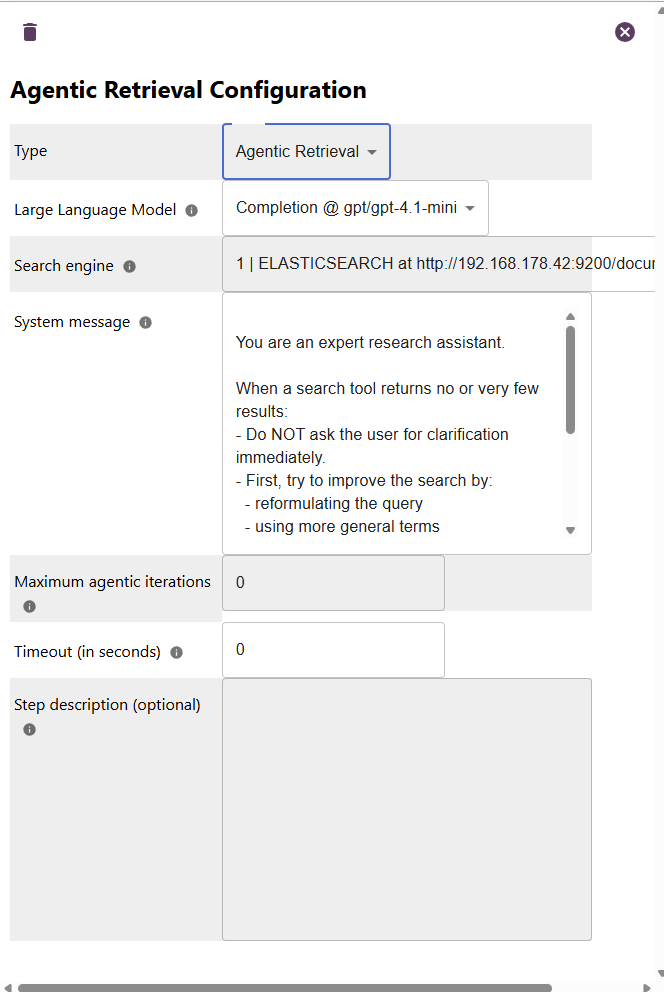
Large language model: here you need to choose one of the defined large language models in Managing Large Language Models
Search Engine: this allows the LLM to retrieve individual documents from the search index when it thinks it is reasonable to do so. Please note that access to documents is restricted however by the user or agent permissions which calls the process.
System message: this prompt allows to steer the agentic processing, i.e., tell how to return results, how extensive research should be done.
Maximum agentic iterations: default is 10. This names the number of iterations the process is allowed to take to solve the task at hand.
Timeout (in seconds): default is 10 minutes. This tells when to terminate the entire agentic loop.