Transparenz und Nachvollziehbarkeit in KI- und RAG-Workflows
17. Dezember 2025
Wenn Ihre KI-Anwendung nicht immer die besten Antworten generiert, liegt es eventuell an nicht optimal konfigurierten Query-Pipelines. Hierfür können die Gründe vielfältig und manchmal komplexer zu beheben sein. Die Retrieval Suite bietet daher ab sofort tiefere Einblicke in die Queryabfragen.
Hintergrund
Retrieval Augmented Generation (RAG) ist eine der zentralen Stützen moderner KI-Workflows. Wie wir in unserem Blogbeitrag Training von LLMs vs. Retrieval Augmented Generation erläutert haben, greift KI entweder direkt auf Inhalte zu oder nutzt eine Vektordatenbank oder Suchmaschine um vorhandenes Wissen schnell aufzufinden.
Allerdings können nicht alle Möglichen Treffern analysiert werden, um die beste Antwort zu generieren. Die KI muss sich auf die ersten zehn bis zwanzig Ergebnisse beschränken. Warum? Da jede Analyse eines Dokuments Zeit (und Token) verbraucht und damit die LLM-Kosten steigen während die Usability rapide abnimmt.
Relevanz
Hier kommt die Suchrelevanz ins Spiel. Relevanz ist ein recht altes Konzept und misst, ob ein Dokument eine Frage tatsächlich beantwortet (relevant ist). Daher sorgen als Teil der Suchmaschine Bewertungs- und Ranking-Algorithmen dafür, dass die relevantesten Ergebnisse als erstes angezeigt werden.
Im Gegenzug gilt, dass nur wenn die ersten Suchergebnisse die relevantesten sind, die KI dem Nutzer (oder Agenten) eine sinnvolle Antwort geben.
Es gibt jedoch ein großes “Aber”.
Google hat uns jahrzehntelang darauf trainiert, in gute Keyword-Suchen einzugeben. In KI-Workflows und Chat-Oberflächen wird dieses Konzept jedoch über Bord geworfen. Nutzereingaben werden immer länger, und weitere Kontexte (wie der Chatverlauf) müssen berücksichtigt werden. Moderne KI-Frameworks und -Toolkits senden zudem häufig nicht nur eine Anfrage, sondern mehrere Anfragen nacheinander in kurzer Zeit.
Die Use Cases sind vielfältig: Nutzer wünschen sich beispielsweise eine schnelle Antwort auf eine simple Frage, oder eine Liste mit Arbeitsschritten oder eine Zusammenfassung mehrerer Dokumente. Daher benötigt man (leicht) unterschiedliche, aber mehrere Workflows um die richtigen Antworten (schnell) zu generieren.
Wie lässt sich also verstehen, was gerade passiert und warum die Antworten der KI nicht richtig oder nicht präzise sind?
RAG-Ausführungen verstehen
Eine besondere Herausforderung bei Retrieval Augmented Generation (RAG) ist die Vielfalt potenzieller Eingaben in Kombination mit den Erwartungen der Nutzer. Selbst wenn Millionen von Dokumenten mit unterschiedlichsten Inhaltstypen in Ihrer Vektorsuche indexiert sind, müssen die relevantesten auch gefunden werden.
Wie erkennen Sie also in Ihrer KI, was gut funktioniert und wo noch Optimierungsbedarf besteht? Die Auswertung von Log-Dateien ist mühsam und skaliert nicht. Insbesondere bei vielen gleichzeitigen Verbindungen verliert man garantiert den Überblick.
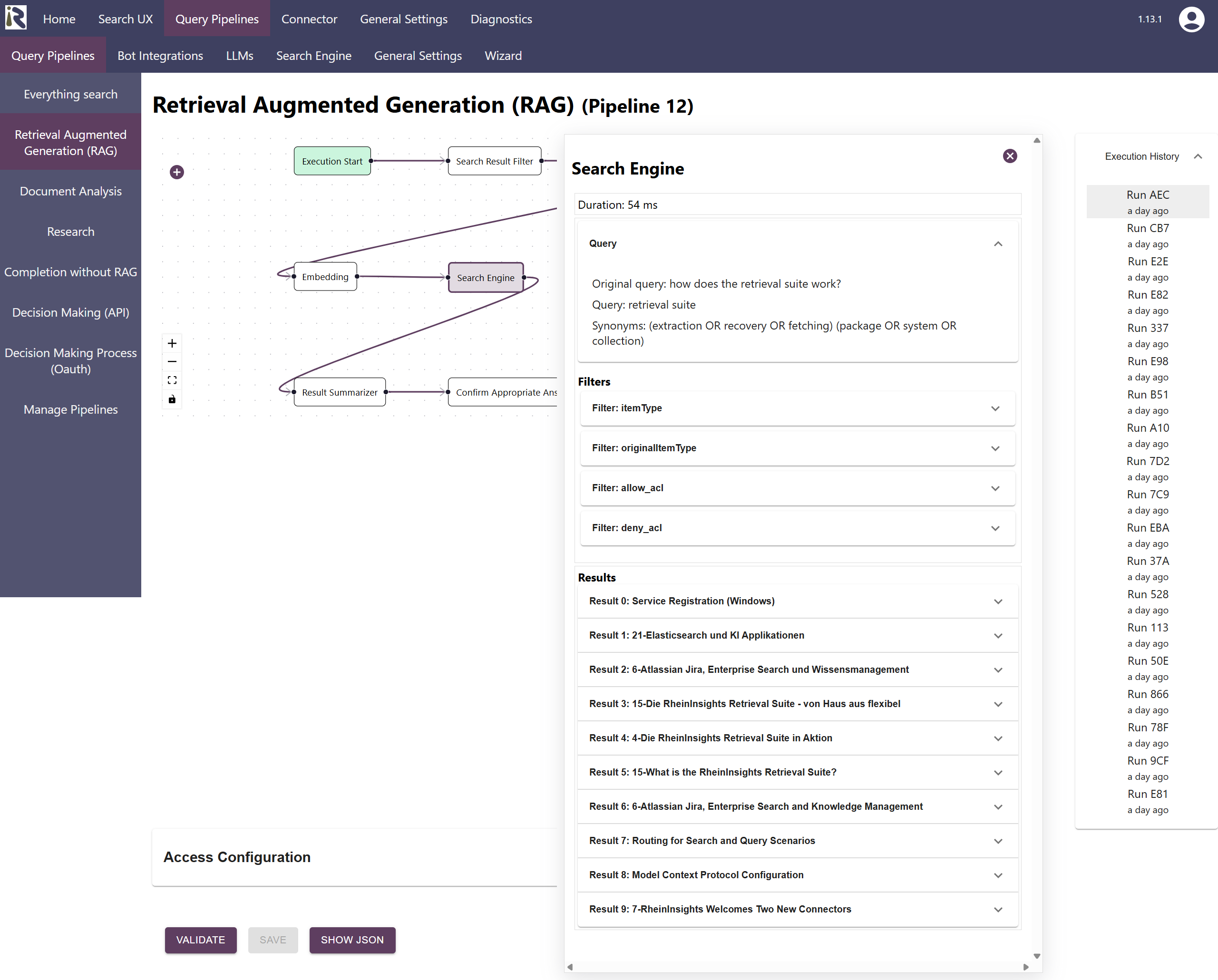
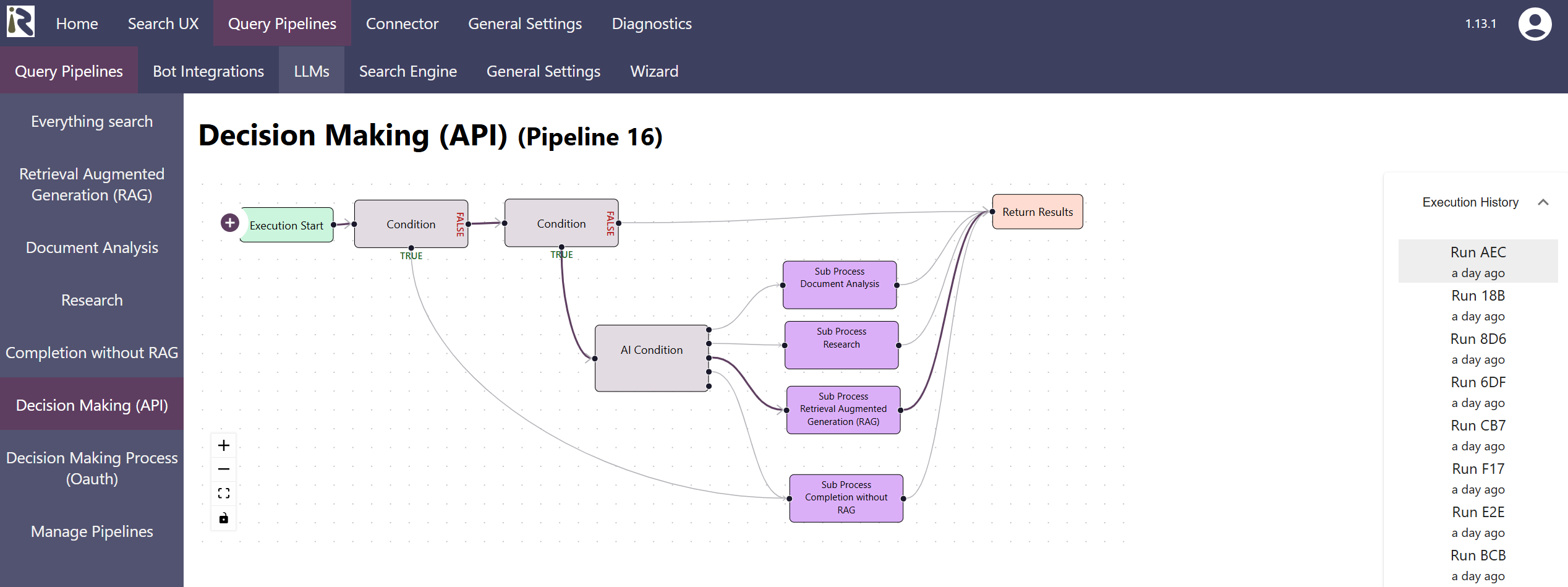
Daher bietet unsere Retrieval Suite ab sofort detaillierte Ausführungsverläufe für ihre Abfragepipelines und die konfigurierten Workflows. Wenn Sie das Logging aktivieren, sehen Sie, welche Pipelines ausgeführt wurden, welche Entscheidungen getroffen wurden und wie die einzelnen Transformationsschritte die Eingaben auf dem Weg zu einem Ergebnis verändert haben.
Daher wird es ein Kinderspiel zu verstehen, warum ein Ausführungsablauf erfolgreich war oder warum ein anderer fehlgeschlagen ist.