Training of LLMs vs. Retrieval Augmented Generation
November 15, 2025
Rapid and precise access to knowledge is important for AI chat bots. In this blog post we discuss the options to provide textual knowledge to your application and the respective advantages.
All options have in common that we utilize a large language model. In the first option described, the knowledge stems from the neural network itself which will be further fine-tuned towards your needs. The second option is retrieval augmented generation where you use a search engine in combination with the large language model. In this case, the actual knowledge comes from the search results and is further processed to answer the user input.

Fine-Tuning of Large Language Models
A large language model (LLM) completes sequences of strings. It leverages statistical knowledge to complete input prompts. State-of-the-art LLMs do this with extreme precision so that prompts are extremely well answered. However, such LLMs cannot answer questions which go beyond publicly accessible knowledge. Questions which can only be answered with internal knowledge, cannot be answered by an out of the box LLM. As it was never trained with your data and for your use cases.
Therefore, you can decide to fine-tune a model with your particular training data. It is obvious that you do not train an LLM from scratch. But you take one of the existing commercial or free models as a starting point and actually fine-tune it. This has the advantage that you do not need the entire internet as training data but you can start with relatively small sets of training data. Starting around a few hundred or thousand records. The outcome is a “custom” LLM which handles your use cases.
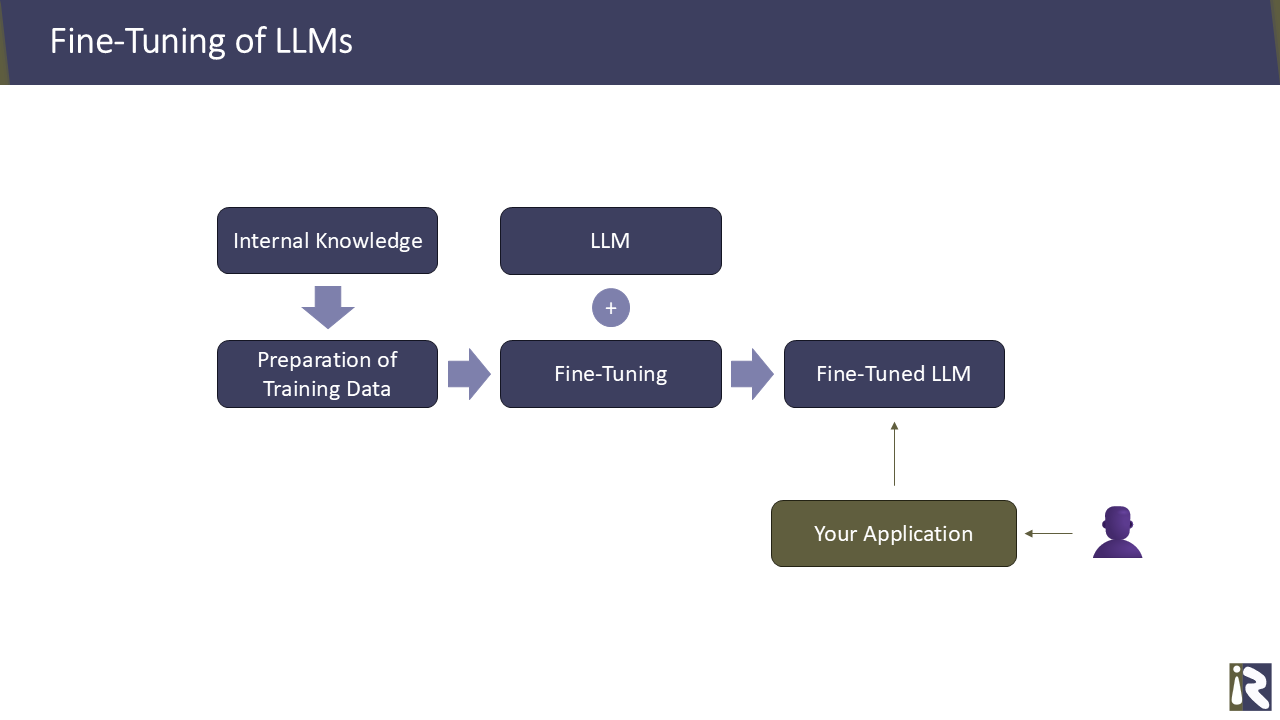
✅ The advantage of this approach is that the LLM will generate answers really fast. When prompting your custom model, it immediately starts generating answers. The reason is that you are working with relatively small prompts which can be answered much faster.
❎ However, please have in mind the initial training costs and that changing knowledge yields retraining (another fine-tuning round) of your custom model. So in volatile environments this approach might be too limited. Also security concepts and fine-granular permissions towards the underlying knowledge cannot be implemented with this approach. Moreover, you use your internal knowledge to train the LLM. If you do not want to expose any of it to a cloud provider, then you need to train an on-premises model such as GPT-OSS, Llama or similar on your own hardware.
Retrieval Augmented Generation and Grounding
On the other hand, one can use a search engine to deliver search results to the LLM. A fine-tuning of the LLM is in this case not needed.
In this case, rather than answering the user prompt through the LLM, the prompt (or query) is sent to the search engine first. The top search results will then be provided with the original prompt to the LLM and the LLM recombines these to an answer.
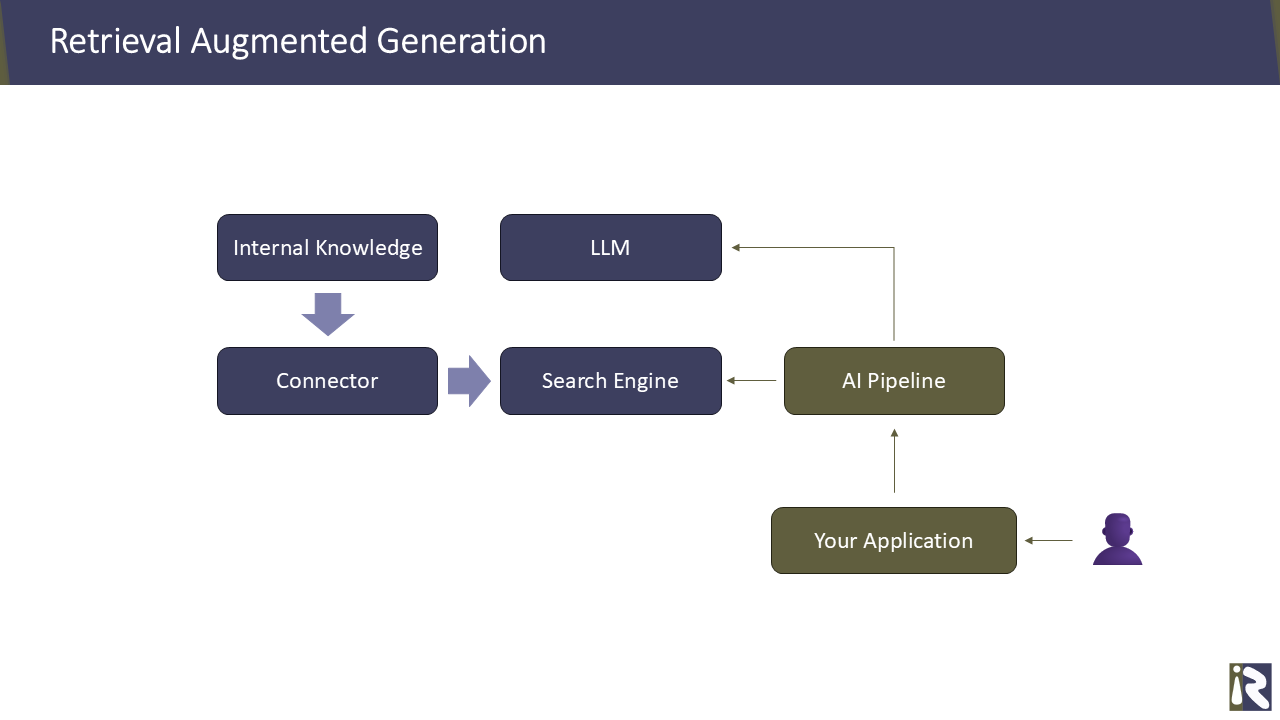
✅ The advantage of this approach are the relatively low setup costs. You do not need to train the LLM which saves computational cost as well as the time from your colleagues or yourself. Also if knowledge changes over time, you only need to reindex the new data or remove outdated information from the search index.
❎ As written above, the advantage of having a fine-tuned LLM is its response speed. Providing search results (and documents) makes the actual prompts longer. So the LLM’s response will be slightly delayed for about a second or two. This might be insufficient for applications where users expect a realtime response. However in chat scenarios response times are extremely fine.
Comparison
Fine-Tuned-LLMs | RAG and Grounding | |
|---|---|---|
Response time |
|
|
Cost of training |
|
|
Systems involved |
Fine-tuned LLM |
LLM, Search Engine and Connector / Crawler |
Handling of new knowledge |
Retraining |
Reindexing |
Introducing fine-grained permissions |
Not supported |
Supported |
Change of the underlying LLM |
Not possible without retraining |
Anytime (for completions) |