Training von LLMs oder Retrieval Augmented Generation?
15. November 2025
Für KI-Chatbots ist ein schneller und präziser Zugriff auf Wissen unerlässlich. In diesem Blogbeitrag erörtern daher Möglichkeiten, Ihrer Anwendung textuelles Wissen bereitzustellen und diskutieren Vor- und Nachteile.
Die Optionen, die wir aufzeigen, haben jeweils ein LLM als Kern. Bei der ersten Variante, die wir aufzeigen, stammt das Wissen direkt aus dem neuronalen Netzwerk eines nachtrainierten LLMs. Dieses wird mit relevantem Wissen nachtraininert um passende Antworten zu liefern. Die zweite Variante ist Retrieval Augmented Generation, bei der eine Suchmaschine in Kombination mit einem LLM verwendet wird. In diesem Fall stammt das eigentliche Wissen aus den Suchergebnissen und wird mit Hilfe eines LLM kombiniert, um die Frage des Benutzers zu beantworten.

Fine-Tuning von Large Language Modellen
Ein großes Sprachmodell (LLM) vervollständigt Eingaben, die an es gesendet wurden. Es nutzt dabei statistisches Wissen, um Prompts zu vervollständigen. Moderne LLMs arbeiten dabei mit höchster Präzision, sodass Anfragen sehr zuverlässig beantwortet werden. Allerdings können solche LLMs keine Fragen beantworten, die über öffentlich zugängliches Wissen hinausgehen. Fragen, die nur mit internem Wissen beantwortet werden können, lassen sich mit einem Standard-LLM nicht beantworten. Dies liegt daran, dass es nie mit Ihren Daten und für Ihre Use-Cases trainiert wurde.
Daher ist ein Ansatz, ein LLM mit Ihren spezifischen Trainingsdaten zu fine-tunen (nachtrainieren). Natürlich trainiert man kein LLM von Grund auf neu. Stattdessen verwendet man eines der vorhandenen kommerziellen oder kostenlosen Modelle als Ausgangspunkt und dieses wird dann nachjustiert. Dies hat den Vorteil, dass Sie nicht das gesamte Internet als Trainingsdaten benötigen, sondern mit relativ kleinen Datensätzen beginnen können – beispielsweise mit einigen Hundert oder Tausend Datensätzen. Das Ergebnis ist ein „maßgeschneidertes“ LLM, das Ihre Anwendungsfälle kennt und beantworten kann.
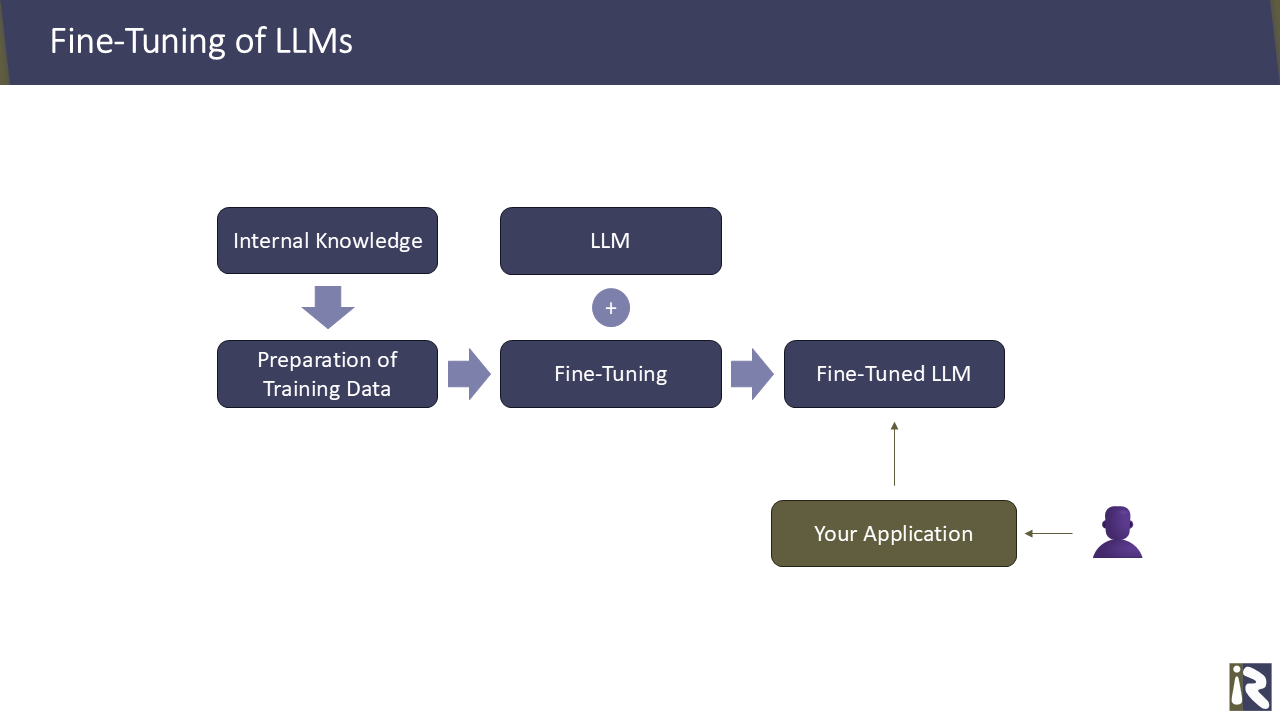
✅ Der Vorteil dieses Ansatzes liegt darin, dass das LLM sehr schnell Antworten generiert. Sobald man einen Promot zum LLM abschickt, beginnt es mit der Generierung von Antworten. Dies liegt daran, dass Sie mit relativ kurzen Prompts arbeiten, die das LLM deutlich schneller verarbeiten und beantworten kann.
❎ Bedenken Sie jedoch, die initialen Trainingskosten. Und dass eine Änderung des Wissens ein erneutes Training (ein weiteres Fine-Tuning) Ihres benutzerdefinierten Modells erfordert. In Use-Cases, wo sich das Wissen regelmäßig ändert oder neues Wissen hinzukommt, ist dieser Ansatz möglicherweise zu eingeschränkt. Auch Security-Trimming und feingranulare Berechtigungen für das zugrundeliegende Wissen lassen sich mit diesem Ansatz nicht implementieren. Darüber hinaus benötigt es internes Wissen zum Trainieren des LLMs. Wenn Sie dieses Wissen einem Cloud-Anbieter nicht offenlegen möchten, können und müssen Sie ein lokales Modell wie GPT-OSS, Llama oder ein ähnliches auf eigener Hardware trainieren.
Retrieval Augmented Generation und Grounding
Alternativ kann man eine Suchmaschine verwenden, um Suchergebnisse an das LLM zu übermitteln. Ein Fine-Tuning eines LLMs ist in diesem Fall nicht erforderlich.
Anstatt die Benutzeranfrage direkt durch das LLM beantworten zu lassen, wird in diesem Ansatz der Prompt (oder die Suchanfrage) zunächst an die Suchmaschine gesendet. Die besten Suchergebnisse werden dann zusammen mit dem ursprünglichen Prompt an das LLM übermittelt, das diese zu einer Antwort kombiniert.
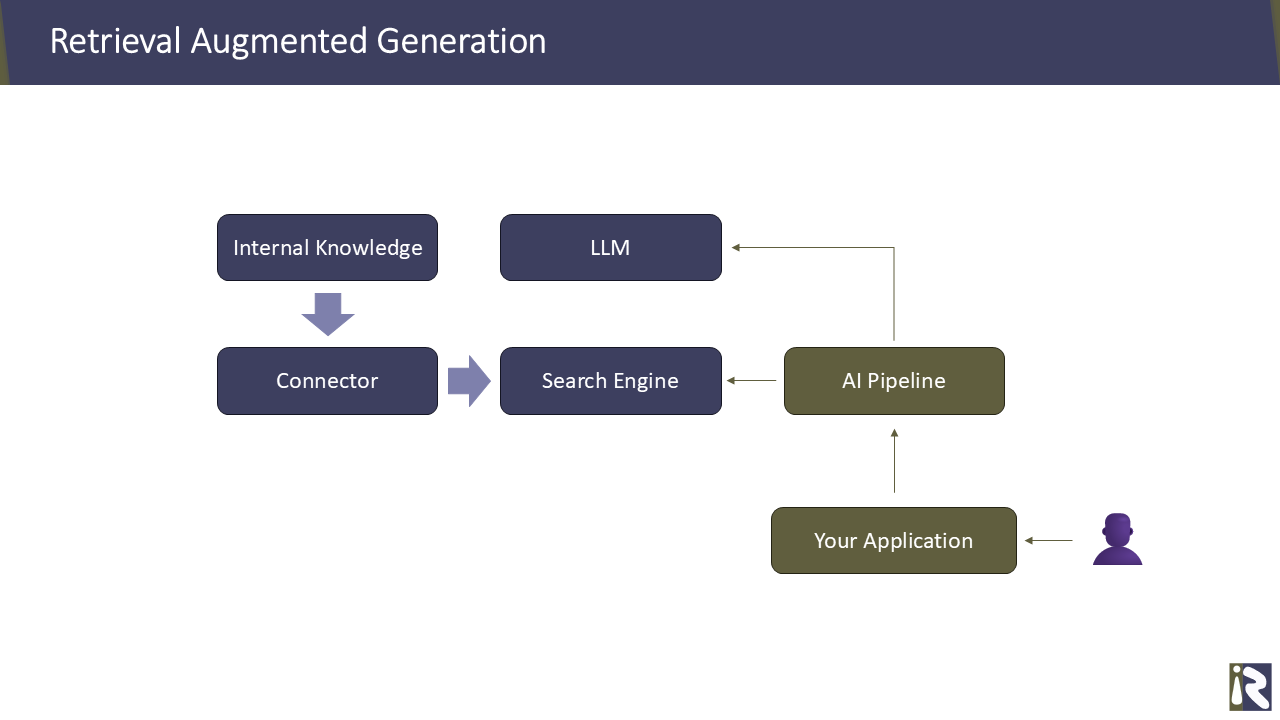
✅ Der Vorteil dieses Ansatzes liegt in den vergleichsweise geringen Startkosten. Das Training des LLM entfällt gänzlich, was erhebliche Rechenkosten (sog. harte Kosten) und Zeit für Ihre Kollegen und Sie selbst (sog. softe Kosten) spart. Ändert sich das Wissen im Laufe der Zeit, müssen Sie lediglich die neuen Daten neu indizieren oder veraltete Informationen aus dem Suchindex entfernen. Gute Konnektoren machen dies automatisch.
❎ Wie bereits erwähnt, liegt der Vorteil eines feinabgestimmten LLMs in seiner Reaktionsgeschwindigkeit. Die Bereitstellung von Suchergebnissen (und Dokumenten) macht die Prompts, welche an das LLM geschickt werden, deutlich länger. Daher verzögert sich die Antwort des LLMs regelmäßig um ein bis zwei Sekunden. Dies kann für Anwendungen, die eine Echtzeitantwort erfordern, unzureichend sein (etwa ein Avatar). In Use-Cases mit Chat, wie Copilot, hingegen sind die Reaktionszeiten absolut hinreichend und akzeptabel.
Übersicht
Fine-Tuned-LLMs | RAG und Grounding | |
|---|---|---|
Reaktionszeit |
Schnell |
Recht schnell |
Trainingskosten |
Hoch |
Keine |
Involvierte Systeme in der IT Architektur |
|
LLM (Standard), Suchmaschine und Konnektor bzw. Crawler |
Umgang mit neuem Wissen |
Retraining (recht aufwändig) |
Indexieren (extrem günstig) |
Arbeit mit detaillierten Zugrifssberechtigungen |
Nicht unterstützt |
Unterstützt |
Änderung des zugrunde liegenden LLMs |
Nicht möglich |
Jederzeit |