Wie kommt relevantes Unternehmenswissen in Open WebUI?
9. Dezember 2025
Open WebUI ist ein Interface für Interaktionen mit KI und LLMs. Es kann in der eigenen Umgebung gehostet werden oder kommt als Cloudvariante. Zudem ist es einfach zu bedienen und bietet eine solide Grundlage für Ihr unternehmensweites KI-Projekt. Doch wie erhalten Sie relevante Antworten basierend auf Ihrem Unternehmenswissen?

Keine relevanten Antworten, fehlendes Wissen oder fehlendes Berechtigungsmodell?
Open WebUI verfügt über eine eigene Vektordatenbank, die zum Indexieren von internem Wissen genutzt werden kann. Dennoch ergeben sich häufig folgende Fragestellungen:
Die generierten Antworten basieren nicht auf den relevantesten Dokumenten oder enthalten ähnliche aber nicht zutreffende Informationen (Halluzinationen).
Die Antworten basieren auf Wissen, welches nicht für alle Benutzer zugänglich ist. Wie kann man Berechtigungen abbilden?
Es fehlen weitere Quellen im Open WebUI-Suchindex. Beispielsweise SharePoint, Teams, Zendesk, Zammad, SAP SuccessFactors, Drupal, Websites, Slack, usw.
In dem Fall schlagen wir einen etwas anderen Ansatz vor, bei dem wir die Erweiterbarkeit von Open WebUI ausnutzen.
Open WebUI ermöglicht es nämlich Funktionen (z.B. Pipes) zu implementieren und diese als eigenes Modell zu registrieren. Mit diesen Modellen können die Nutzenden dann interagieren und diese Modelle können z.B. insbesondere eine standalone Suchmaschine oder unserer Retrieval Suite ansprechen.
Dadurch werden die oben genannten Punkte wie folgt gelöst.
Relevanz
Generell empfehlen wir die Verwendung einer Suchmaschine oder Vektordatenbank stets mit hybrider Suche. Denn eine reine Vektorsuche liefert zwar gute aber oft nicht die relevantesten Ergebnisse.
Zudem müssen Sie die Suchanfragen entsprechend vorverarbeiten, um eine optimale Funktion der Hybridsuche zu gewährleisten.
Beachten Sie, dass Open WebUI eine Option zum Aktivieren der Hybridsuche bietet, die aber standardmäßig deaktiviert ist. Sollten Sie lediglich Relevanzprobleme haben, könnte dies schon eine deutliche Steigerung der Antwortqualität bewirken.
Secure Search and Security Trimming
Sollten Sie Unternehmenswissen anbinden, dann sollte die Vektordatenbank, bzw. die Vektorsuche auch das Berechtigungsmodell der indexierten Quellen verstehen. Den Ansatz hierfür beschreiben wir in unserem Blog Post (siehe Permission-Based Retrieval Augmented Generation (RAG)).
Um diesen Ansatz zu nutzen muss einerseits der Konnektor neben den eigentlichen Dokumenten auch das Berechtigungsmodell “indexieren”. Anderseits müssen die entsprechenden Filtermethoden in der Open WebUI-Function (bspw. der oben beschriebenen Pipe) implementiert werden.
Als Ergebnis werden dann nur Treffer generiert die relevant sind und auf die der Nutzende im Quellsystem auch Zugriff hat.
Sollten Sie unsere Retrieval Suite nutzen, dann unterstützen unsere Query-Pipelines Security Trimming von Hause aus.
Integration weiterer Wissensquellen
Um weitere Wissensquellen in Open WebUI zu nutzen, können Sie vorhandenen Open-Source-Konnektoren downloaden und nutzen.
Sollten solche Open Source-Konnektoren nicht gut funktionieren oder Ihre Anforderungen nicht erfüllen, bietet unsere Retrieval Suite eine stetig wachsende Liste von derzeit über 40 sofort einsatzbereiten Konnektoren für mehr als zehn Suchmaschinen und Vektordatenbanken.
Aufbau der Function
Der Aufbau der Function sieht dann im Wesentlichen wie folgt aus:
Die Function (Pipe) in Open WebUI erhält als Eingabeparameter im wesentlichen den Nutzerkontext, einen Teil der Chathistorie (Chat-Kontext) und als Teil dessen den aktuellen Prompt.
Sie extrahiert den aktuellen Benutzer (als UPN) aus den Eingabeparametern, ebenso wie den Kontext und den aktuellen Prompt.
Die Function muss dann das Embedding (also der Vektor) der Nutzereingabe für die Vektorsuche mit Hilfe eines LLMs erzeugen. Hierbei ist wichtig, dass das Embeddingmodell das gleiche Modell, wie zum Zeitpunkt der Indexierung der Daten, ist.
Die Keyword-Query wird dann noch für die hybride Suche optimiert (lange Eingaben führen zu keinen Treffern in der Keyword-Suche und man endet wiederum in der reinen Vektorsuche)
Dann wird noch kurz der Filter für das Security Trimming errechnet
Mit diesen Informationen wird die Suchmaschine aufgerufen
Die Treffer werden dann mithilfe der Completion API eines LLMs benutzt um eine natürlichsprachige Antwort auf die Nutzereingabe zu formulieren
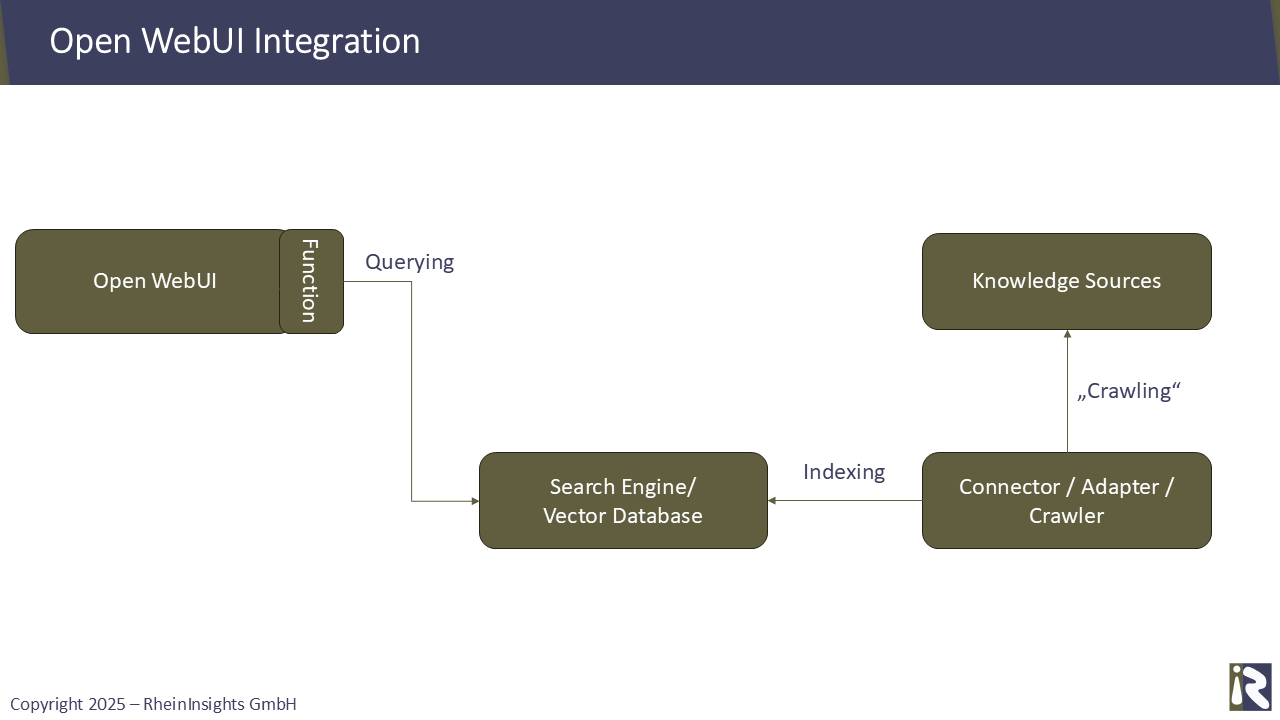
Open Source Architektur
Wenn Sie nur auf Open Source setzen, dann ist die Systemarchitektur wie folgt:
Sie besteht aus
Open WebUI,
unter Umständen einer separaten Suchmaschine oder Vektordatenbank,
sowie der Konnektoren, die Wissen indexieren.
Die Function als Teil von Open WebUI ruft die Suchmaschine auf, um die relevantes Ergebnisse aus dem indexierten Korpus zu erhalten.
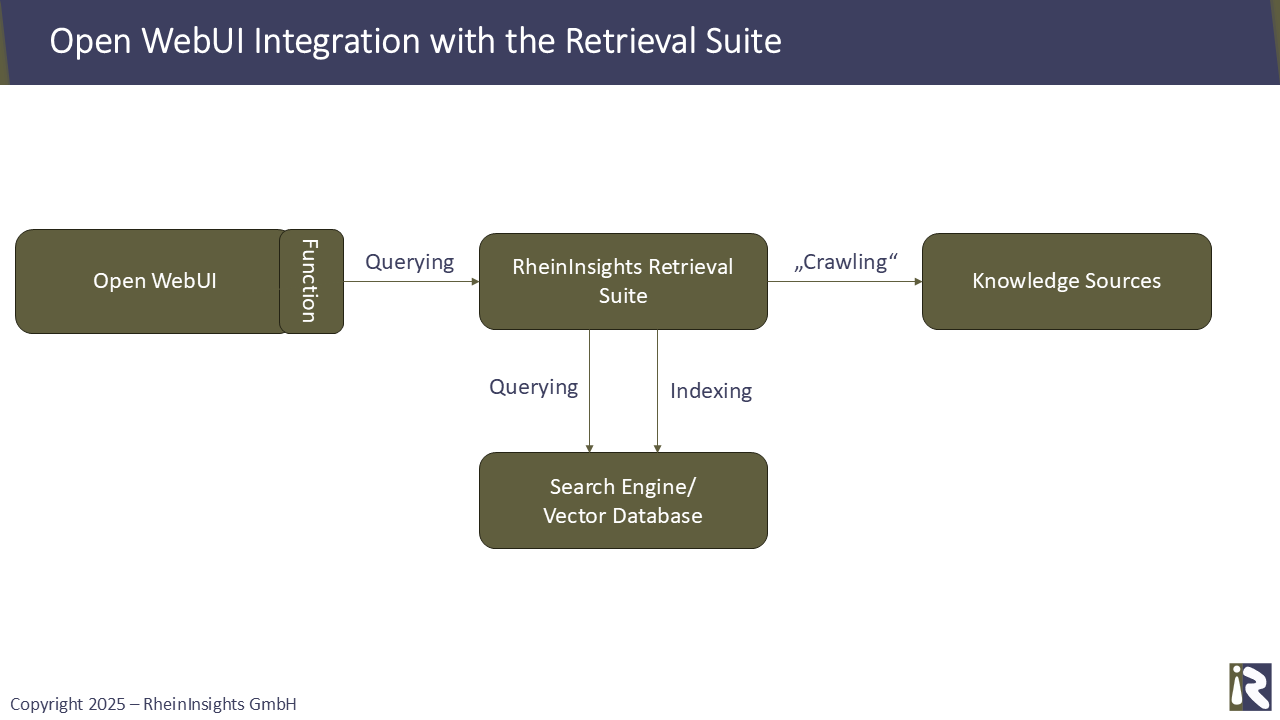
Verwendung der RheinInsights Retrieval Suite
Um den Entwicklungsaufwand zu reduzieren und zügig zum Projekterfolg zu kommen, schlagen wir in einer zweiten Architektur vor, die RheinInsights Retrieval Suite als Middleware zu nutzen.
Dadurch erhalten Sie unsere konfigurierbaren KI-Pipelines und Konnektoren für die Unternehmenssuche. Die Suite hochrelevante Suchergebnisse und generiert passende Antworten auf jede Benutzereingabe - inklusive Security Trimming.
In der Architektur fungiert unsere Retrieval Suite als Middleware, die einerseits die Konnektoren liefert und anderseits die Abfragen aus der Function mit Hilfe der eigenen Query Pipelines bedient.