Transparent AI and RAG Workflows
December 17, 2025
If you are struggling with getting the right answers in your AI application then likely the retrieval workflows are not always optimal. Reasons can be manifold and hard to debug. This is why from now on the Retrieval Suite a UI-based tracing for query execution flows.
Introduction
Retrieval augmented generation (RAG) is one of the main pillars of modern AI workflows. As we discussed in our blog post Training of LLMs vs. Retrieval Augmented Generation, AI accesses current knowledge either directly or it uses a vector database or search engine. However, you cannot iterate over all results to generate the best answer but you must stick with the first ten or twenty results. Why? The analysis of each and every document takes time (and tokens) and in turn LLM cost rises and usability decreases rapidly.
Relevance
This is where search relevance comes into play. Relevance is a pretty old concept and measures if a document actually answers a question. I.e., how relevant it is for the given query. As part of the search engine, scoring and ranking algorithms are responsible to bring the most relevant results to the front.
In turn, only if the first search results are the most relevant results, AI can generate a good responses to the user (or agent). Of course, you can integrate more than ten results into the reasoning, but each additional document comes with a cost.
However, there is a huge but. Google trained us for decades to think in good keyword searches. Within AI workflows and chat interfaces this concept is torned down now. User inputs become longer and longer and additional contexts, such as the conversation history, need to be taken into account. Even worse, modern AI frameworks and toolkits tend to not just send one request but multiple in sequence within short timeframes.
The use cases are manifold: users might want a quick answer to a simple question, a list of work steps, or a summary of several documents. Therefore, several (slightly) different, and thus multiple, workflows are needed to generate the right answers (quickly).
So how do you understand what is going on and why given answers are imprecise?
Understanding RAG Flows
For retrieval augmented generation one particular challenge is the broadnesss of potential inputs combined with user expectations. If you have millions of documents with many different content types indexed in your vector search, you still need to be able to generate the right answers. So you need to find the most relevant documents in your haystack.
If you get started with your own RAG system, how do you understand what works well and where you need to finetune your workflows (or add new ones)? In fact, evaluating log files is a tedious task and does not scale well. In particular if you have many concurrent connections you quickly loose overview.
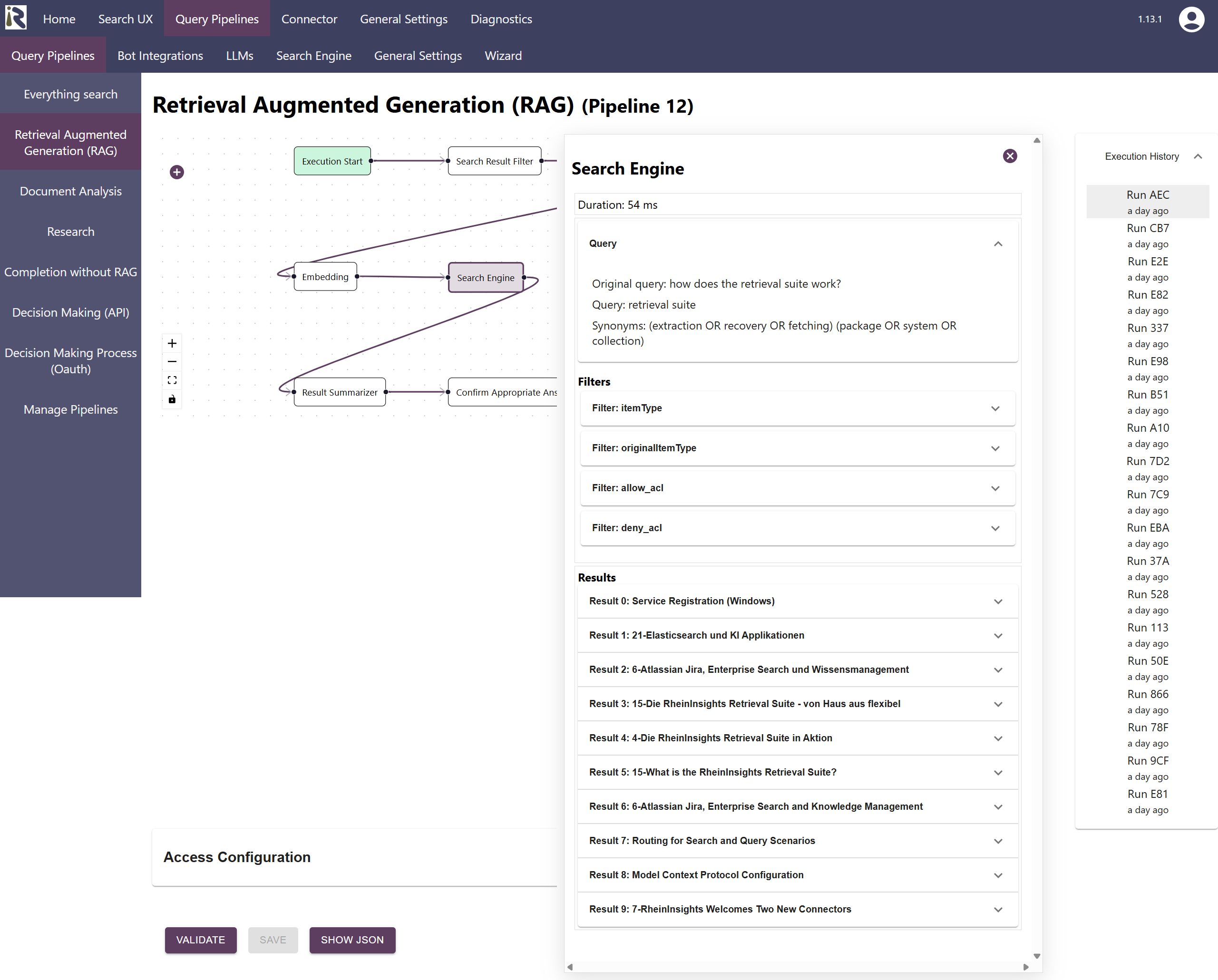
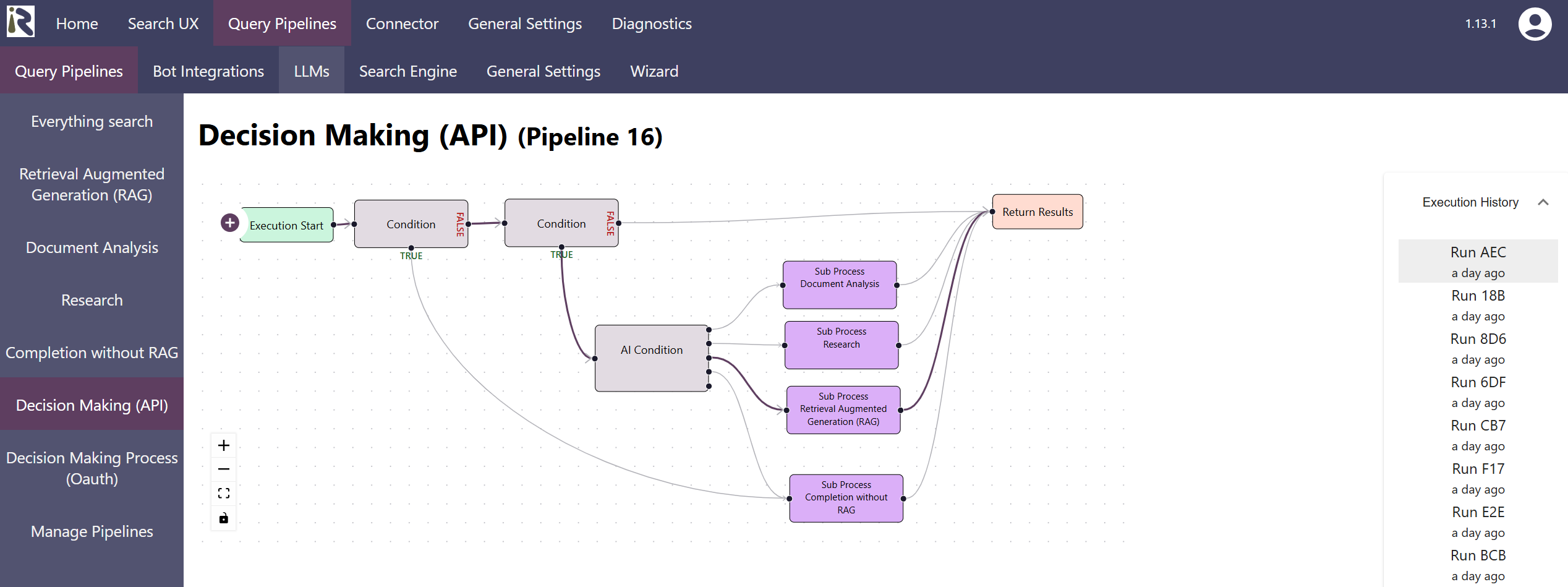
Therefore, from now on our Retrieval Suite offers detailed execution histories for its query pipelines and the configured workflows. Once activated, you see which pipelines were executed, which decisions where made and how the individual transformation steps transformed the inputs on the way to an answer.
This way, it becomes far easier to understand why an execution flow was successful or why it failed.