What Have Federated Search and Model Context Protocol in Common?
January 28, 2026
Model Context Protocol (MCP) is the new silver bullet for tool access and knowledge retrieval. It becomes an integral part of how AI systems will work in future.
In contrast to offering organizations to form their own step by step processes in AI pipelines, modern LLMs first think and then perform the processes internally. This means that whitebox processes become more and more blackbox processes which include taking actions as part of the process.
From a knowledge retrieval standpoint this means that the LLM accesses knowledge sources via MCP as part of the blackbox process. Unless you have a tool like the RheinInsights Retrieval Suite as an MCP provider, you might end up with querying knowledge source individually via MCP.
What did we learn in the past and what might be different with MCP?

Federated Search
Actually, we know the concept of reaching out to systems individually since decades. In enterprise search, this was called federated search. Instead of building one concise and homogenized search index with a strong search engine, one could execute queries directly against the APIs of the content sources. If you had half-way consistent authentication providers in place, this approach even worked with secure search and permissions.
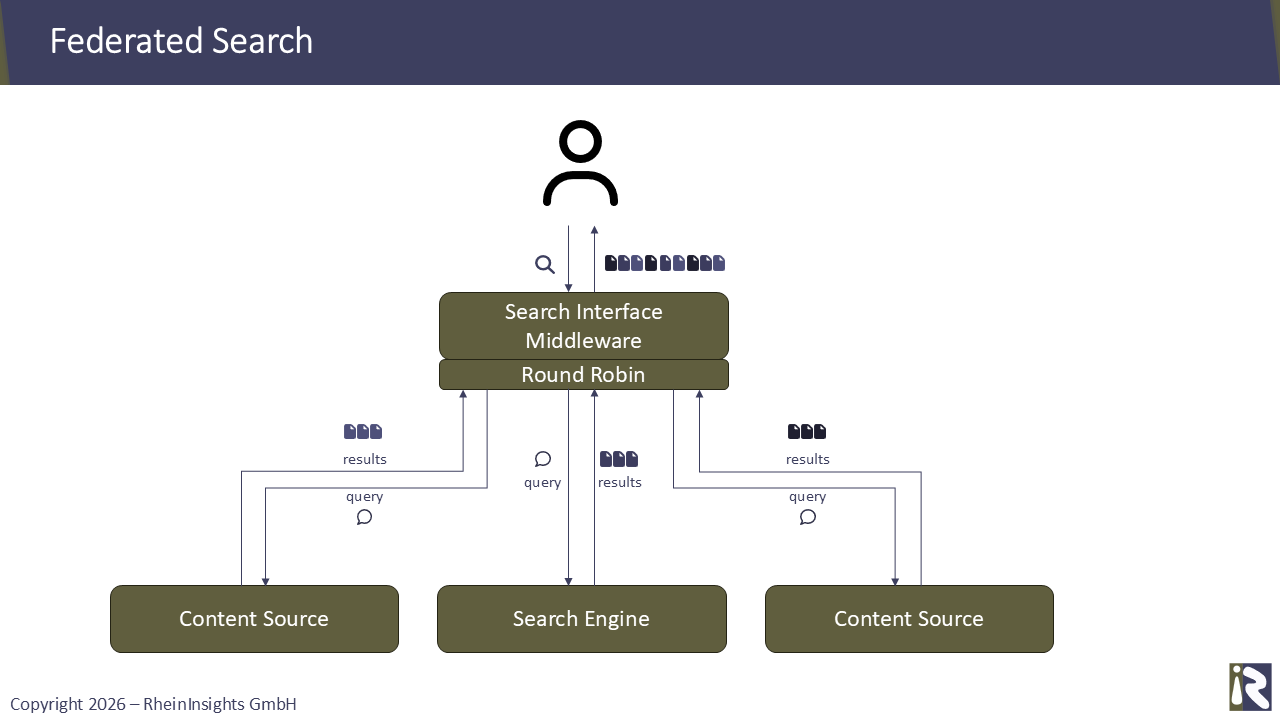
However, it always lacked consistent and good search results. Mainly because in federated you do not receive one result list with one consistent relevancy model. But you only get a list of results from the sources and you need to merge them yourself. For instance, via round robin.
Also, many source systems offer a search API. But, their search capabilities were offered as an early feature but over the course of time, never tuned towards great and relevant results.
Model Context Protocol for Knowledge Retrieval
If an LLM uses MCP to directly connect to an enterprise search, an AI search or a middleware, like our RheinInsights Retrieval Suite, it benefits from securely retrieving the most relevant results.
However, if the approach is to query the search or MCP APIs of the content sources one by one, isn’t this a federated search approach? But what is different now?
The major difference is what LLMs are capable of. In the past, there was a human sitting in front of the PC who was confronted with dozens of potentially irrelevant search results due to the round robin. Now you can use multithreading and the power of your LLMs.
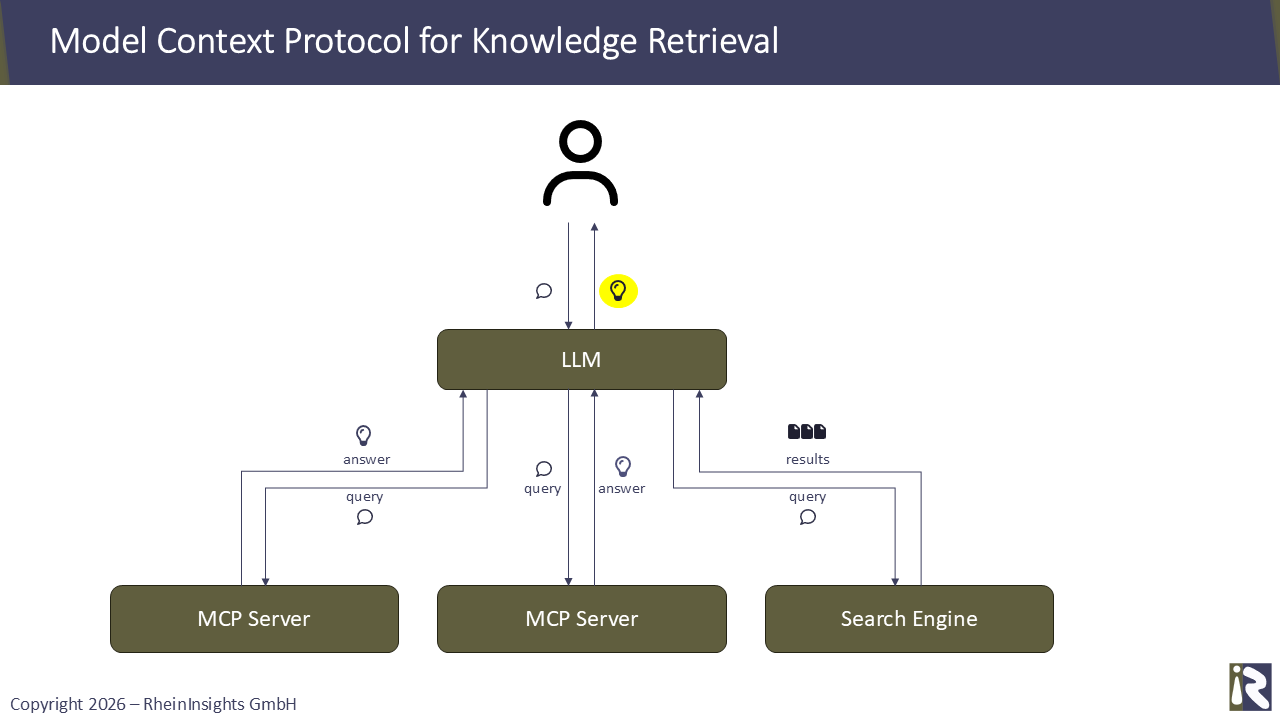
This means that a knowledge retrieval process now looks as follows. The LLM calls multiple MCP servers and ask for knowledge. These either calculate answers on their own or return records. The LLM interprets the information given, potentially dives even more into the data by requesting more details and returns the result.
What Does This Mean?
The answer is most likely significantly better than the results of a federated search. It is also generated in an acceptable timeframe, as the subprocesses can be parallelized.
The approach is expensive. First of all, a lot of heat is generated. And an extremely large number of LLM tokens are consumed. Furthermore, the approach carries the following technical risks:
The quality of the LLM response depends entirely on the quality of the responses from the individual MCP servers or APIs. See our remark with regards to the built-in search engines above.
Retrieving many documents (on-demand) for further (agent-based) analysis can take a very long time.
If documents need to be retrieved and further analyzed, the LLM can encounter rate limiting and be severely slowed down.
MCP vs. Specialized Knowledge Search
Indexing large amounts of data into an enterrpise search or AI search requires a dedicated infrastructure. However, it offers many compelling advantages.
More relevant results are delivered right from the start
These results are available offline and can be analyzed immediately.
This leads to faster and more precise analysis.
As a consequence, the number of LLM tokens consumed and the response time are significantly reduced. Thus, a centralized AI search or the RheinInsights Retrieval Suite saves a lot of costs.