Was verbindet föderierte Suche mit Model Context Protocol?
28. Januar 2026
Das Model Context Protocol (MCP) ist die neue Wollmilchsau für den Tool-Zugriff und Wissenssuche mit KI. Es wird immer mehr zu einem integralen Bestandteil der von KI-Systemen.
Im Gegensatz zu klassischen Verarbeitungsschritten und KI-Workflows, denken aktuelle Generation von Sprachmodellen zunächst Arbeitsschritte vor und führt sie diese dann automatisiert, auch per MCP, aus. Dadurch werden Whitebox-Prozesse zunehmend zu Blackbox-Prozessen, die als solche insbesondere auch Aufrufe auf Umsysteme durchführen.
Aus Sicht des Knowledge Retrievals bedeutet dies, dass das LLM im Rahmen des Blackbox-Prozesses über MCP insbesondere auf Wissen zugreift. Wenn kein zentrales Tool wie die RheinInsights Retrieval Suite oder eine echte Unternehmenssuche als MCP-Server angesprochen wird, werden die Wissensquellen unter Umständen jeweils einzeln und nacheinander per MCP abgefragt.
Ein Blick in die Vergangenheit zeigt, dass wir dies schon einmal als Konzept hatten. Was haben wir hier gelernt und was ist mit MCP - zumindest in der Theorie - anders?

Föderierte Suche
Das Konzept, Systeme einzeln, parallel oder nacheinander, anzusprechen, ist tatsächlich schon seit Jahrzehnten bekannt. In der Unternehmenssuche nannte man dies “föderierte Suche”.
Anstatt einen einzigen, einheitlichen Suchindex einer leistungsstarken Suchmaschine zu erstellen, war es seit jeher verlockend Queries direkt an die APIs der Inhaltsquellen senden. Wenn man die einzelnen Authentifizierungen der Quellsysteme gut aufeinander abgestimmt hat, funktionierte dieser Ansatz sogar mit Berechtigungen. Allerdings mangelte es stets an konsistenten und guten Suchergebnissen.
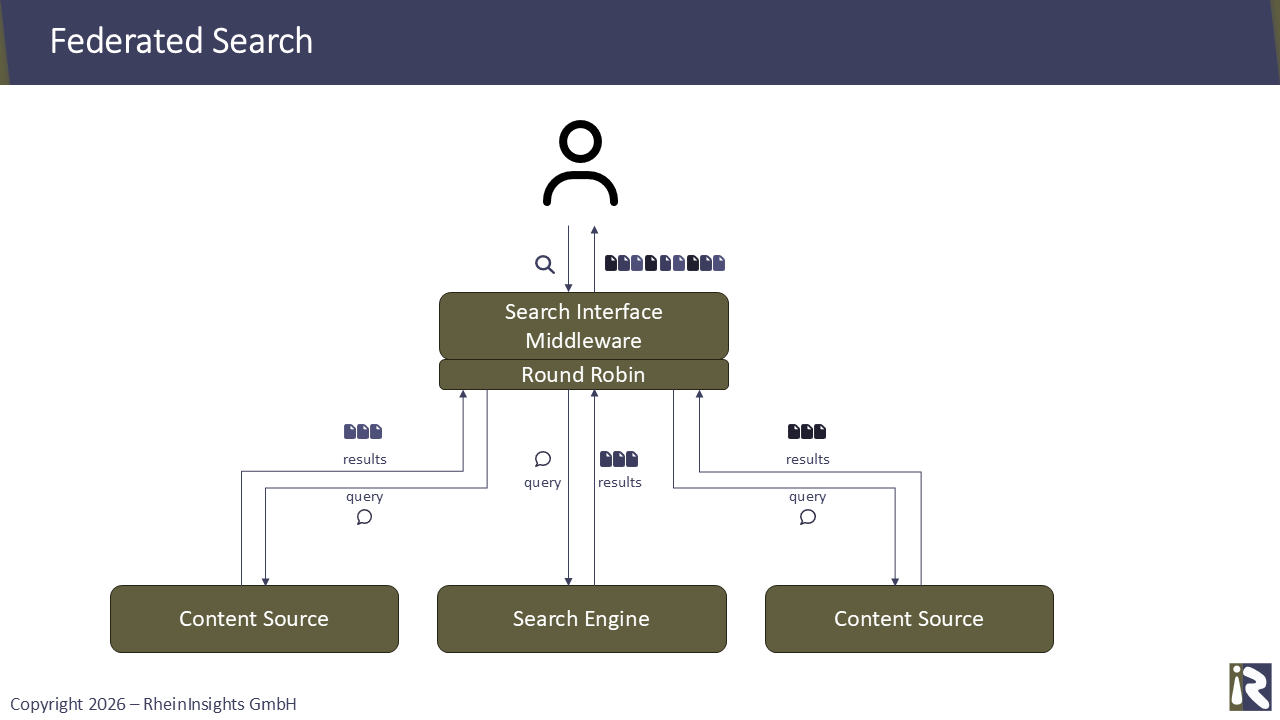
Das liegt vor allem daran, dass man bei föderierten Suchergebnissen keine einheitliche Ergebnisliste mit einem konsistenten Relevanzmodell erhält. Stattdessen bekommt man lediglich eine Ergebnisliste je Quelle und muss diese dann selbst zusammenführen. Hierfür nutzt man beispielsweise das Round-Robin-Verfahren.
Zudem bieten viele Quellsysteme zwar eine Such-API. Jedoch scheint es doch regelmäßig so, dass die Suchfunktion zwar frühzeitig in einem Release eingeführt wurde. Jedoch wurde die Quellsystemsuche im Laufe der Zeit nie auf wirklich gute und relevante Ergebnisse optimiert.
Model Context Protocol und Wissenssuche
Wenn ein Sprachmodell (LLM) nun das Model Context Protocol (MCP) nutzt, um sich direkt mit einer Unternehmenssuche, einer KI-Suche oder einer Middleware wie unserer RheinInsights Retrieval Suite zu verbinden, dann erhält es in der Regel gute Antworten und relevante Treffer zurück. Insbesondere kann hier dann auch leicht Security Trimming angewandt werden.
Wenn das LLM aber die Such- oder MCP-APIs der Inhaltsquellen einzeln abgefragt, handelt es sich dann nicht auch um eine föderierte Suche? Was ist also der Unterschied?
Der größte Unterschied liegt in den Möglichkeiten von LLMs. Früher saß ein Benutzer vor dem PC und sah sich aufgrund des Round-Robin-Verfahrens mit Dutzenden, potenziell irrelevanten Suchergebnissen, konfrontiert. Heute kann theoretisch die Leistungsfähigkeit von LLMs und Multithreading deutlich bessere Ergebnisse erzeugen.
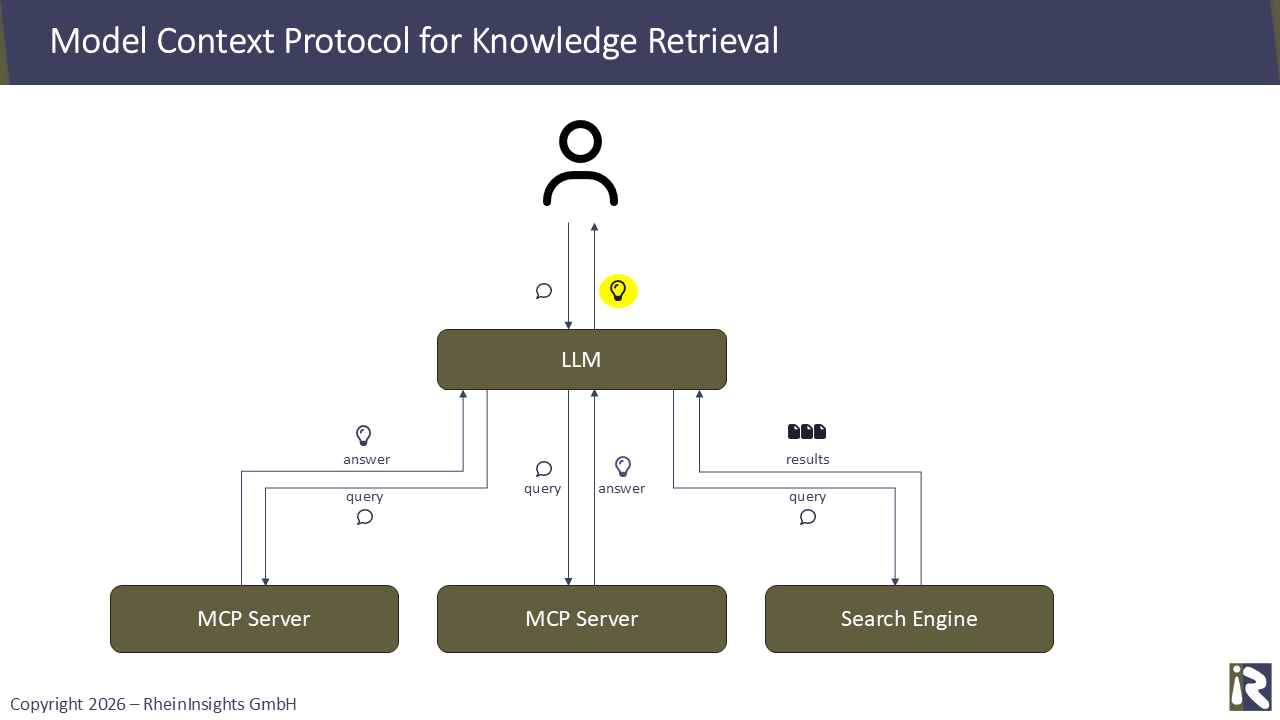
Das bedeutet, dass per MCP Wissen nun wie folgt aufgefunden werden kann. Das LLM spricht mehrere MCP-Server parallel an und fragt nach Informationen. Diese berechnen entweder selbstständig Antworten oder liefern Suchergebnisse oder ganze Dokumente. Das LLM interpretiert die bereitgestellten Informationen, analysiert die Daten gegebenenfalls durch die Anforderung weiterer Details und gibt das Ergebnis zurück.
Die Konsequenz
Was bedeutet das? Die Antwort ist höchstwahrscheinlich deutlich besser als die Ergebnisse der föderierten Suche. Sie wird zudem in akzeptabler Zeit generiert, da der Prozess parallelisiert werden kann.
Aber es wird sehr viel Abwärme erzeugt. Und es werden extrem viele LLM-Tokens verbraucht. Zudem birgt der Ansatz folgende technische Risiken:
die Qualität der Antwort des LLMs steht und fällt mit der Qualität der Antworten der einzelnen MCP Server.
Der (on-demand) Abruf vieler Dokumente zur weiteren (agentischen) Analyse dauert im Zweifel sehr lange
Müssen Dokumente abgerufen und weiter analysiert werden, dann kann das LLM in ein Ratelimiting laufen und stark ausgebremst werden.
MCP vs. Spezialisierte Wissenssuche
Auch wenn das Indexieren vieler Unternehmensdaten eine eigene Infrastruktur nötig macht, hat es weiterhin viele, zwingende Vorteile. Eine zentralisierte KI-Suche oder die RheinInsights Retrieval Suite hingegen spart Kosten. Denn
Schon im ersten Schritt werden relevantere Ergebnisse geliefert.
Diese Ergebnisse sind offline verfügbar und können sofort weiteranalysiert werden
Dies führt zu einer schnelleren und präziseren Analyse
Die Anzahl der verbrauchten LLM Token und die Antwortzeit werden als Konsequenz massiv reduziert.