Using Your Investment into Elasticsearch for AI Applications
July 22, 2025
Elasticsearch is used as a (distributed) search engine and as no-SQL store in a vast amount of organizations. Thus, the question is, can one easily use an investment into an Elasticsearch infrastructure and operations for modern AI applications?
Therefore, in this blog post, we will outline which components are needed to build AI applications on top of a plain Elasticsearch installation.
Retrieval Augmented Generation and Grounding
As described in our previous blog posts, large language models (LLMs), such as GPT, Deepseek or Llama, can answer many questions based on the training data itself. But when doing so, there is always the risk of hallucination. Here the LLM gives entirely wrong answers. Overall, an LLM is still just a (very strong) random character generator which does not do any research during completions.
Therefore, if real knowledge is needed, you leverage retrieval augmented generation (RAG). Here, you combine the LLM with a (vector) search engine which produces far better results. For a general introduction, see for instance our documentation RheinInsights - Documentation - Retrieval Augmented Generation. Moreover, grounding can take permissions into account, as we outline in our blog post RheinInsights - Insights - Permission-Based Retrieval Augmented Generation (RAG).
Elasticsearch and Retrieval Augmented Generation
Therefore, when it comes to answering questions, you would always combine an LLMs with knowledge which you store in search engines. The reason is obvious: only a search engine can give you the most relevant results to a user query in a very short amount of time. A lookup in a knowledge source itself would be far too slow and computationally too expensive.
And here, Elasticsearch comes into play. Elasticsearch is a widely used search engine. It supports keyword search, vector search and also efficient filtering. Moreover, its installations scale well with many indexed documents.
Indexing Data into Elasticsearch
As for all RAG and enterprise search scenarios, one distinguishes between indexing and query time. Only if both goes hand in hand, you will have a the grounding which you are looking for.
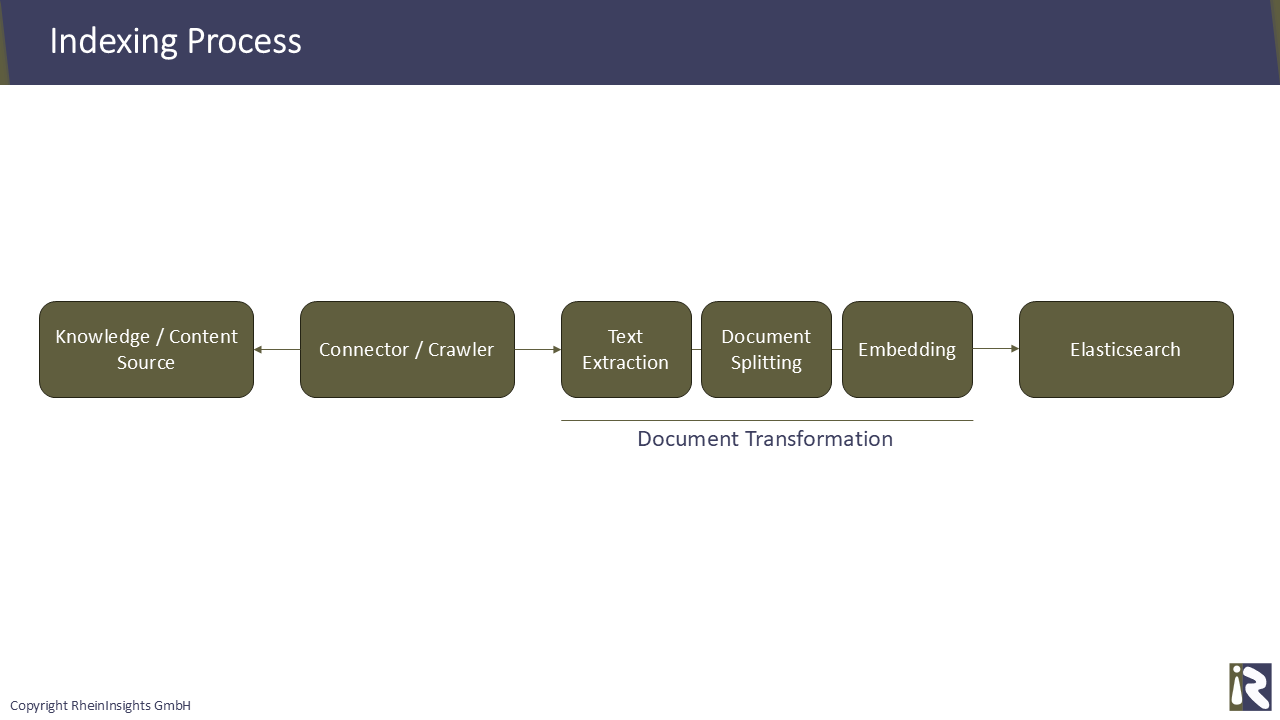
Thus, during indexing, the following steps are usually done:
Crawling of all relevant data, for instance Confluence, Github, SAP SuccessFactors or M365 data.
Text extraction. You convert binary and HTML data for each individual document into plain text
Document splitting. In this step very long documents are moreover split into smaller parts. The reason is that extremely long documents might appear less relevant than parts of it. And during the generation step below, you will run into length limitations.
Calculation of embeddings. Here you create a vector which you can index. The vector is usually also generated with your favorite LLM, for instance OpenAI’s text-embedding-ada-002 or mxbai-embed-large. This vector is then indexed along with the textual data and any metadata you provide.
Submission to Elasticsearch
Interacting with the Data
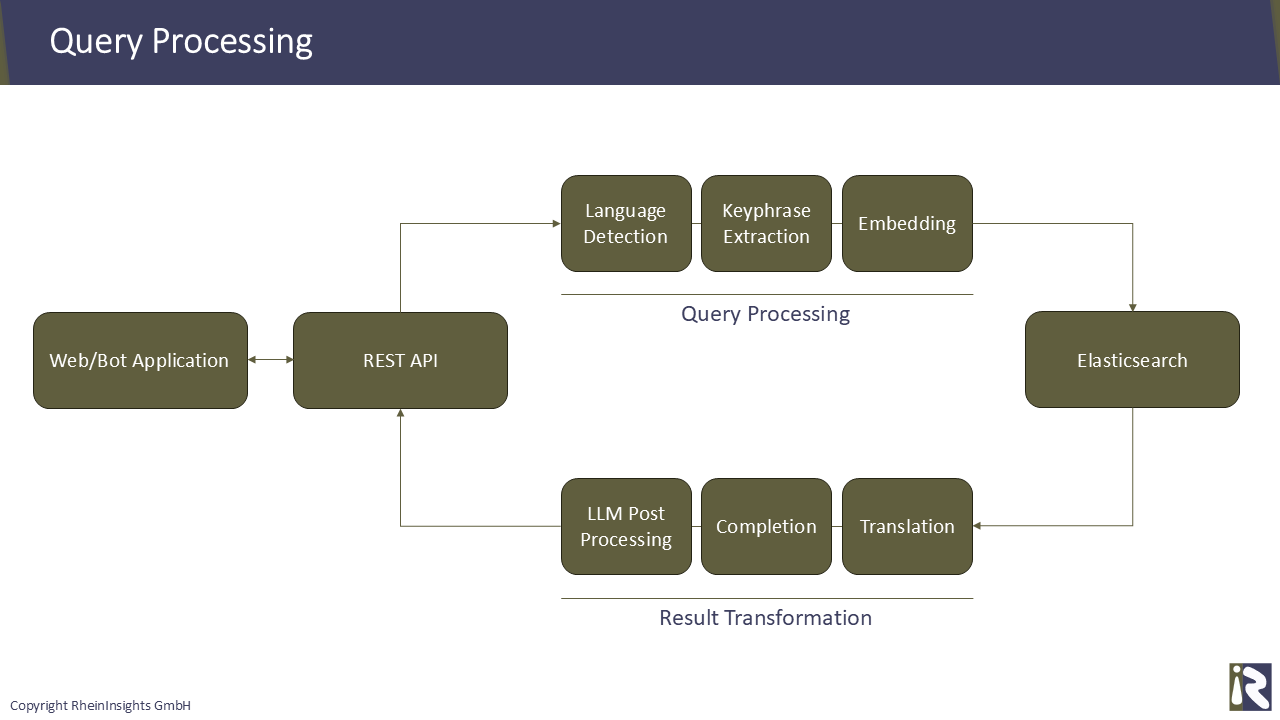
Afterwards, a user can interact with the AI application, for instance a bot, and get answers. Meaning that if the application decides that a knowledge question is stated, it queries Elasticsearch. In order to do so, at least, the following steps are performed
Generating an embedding for the user query. So that you have a vector which you can use for vector search again.
Obviously, here you need to use exactly the same embedding model as in Step 4 above. If this is not the case, then usually the vector dimensions differ. This means, you will then not be able to execute the query at all.Then you use Elasticsearch’s REST API to execute the vector search query.
Generation. Use the top N search results and let the LLM generate an answer for the stated user query. Here a little prompt engineering is needed. In particular, LLMs tend to differ heavily in their answering behavior.
You can also perform more steps during query processing and result transformation. Here, refer to our blog post on using multilingual data RheinInsights - Insights - Translations as Part of Modern LLM Pipelines.
The result can then be presented to the user. The LLM and post processing can even add references to the search results so that the user has a chance to do further research on her own.
Please note that we do not recommend to use a plain vector search against Elasticsearch. The search results tend to be irrelevant. But we always perform hybrid searches.
A hybrid search is a keyword search in combination with a vector search. It combines the advantages of vector and keyword search: it will always generate search results and will be less narrow than keyword query results. But the keyword query makes sure that the most relevant results are usually the most relevant.
The Result
Both, indexing as well as querying the data does impose changes to the Elasticsearch installation. So you can start using your deployment for your AI case. You only need to generate a search index with an appropriate schema.
In turn, however, you can build your AI application based on the existing Elasticsearch installation. With hybrid search in place, you will receive relevant search results which support your AI use case.
The RheinInsights Retrieval Suite
Our product, the RheinInsights Retrieval Suite is brings in the components listed above for all supported search engines:
It brings enterprise search connectors which help you jump-starting the indexing e.g. into Elasticsearch.
All connectors also support the permission model of the content sources, so that you can implement secure search or permission-based grounding.
Our Suite also brings pre-configured indexing pipelines which process the data before indexing in Elasticsearch.
On the other hand, our Suite also provides the necessary query pipelines.
Users can state questions and receive great answers.
These answers are grounded based on the permissions the users have. This makes sure that also in the Elasticsearch RAG application knowledge is never lost.
And it supports deep researching if the generated answers are not good enough.