Elasticsearch und KI Applikationen
22. Juli 2025
Elasticsearch wird in zahlreichen Organisationen als (verteilte) Suchmaschine und als No-SQL-Datenbank eingesetzt. Daher stellt sich regelmäßig die Frage: Lässt sich die schon bestehende Instanz für moderne KI-Anwendungen sinnvoll nutzen? Denn damit erspart man sich weitere Kosten für den Betrieb und das Deployment einer neuen Suchmaschine.
In diesem Blogpost erläutern wir daher, welche Komponenten für die Entwicklung von KI-Anwendungen auf Basis einer schon bestehenden Elasticsearch-Installation erforderlich sind.
Retrieval Augmented Generation und Grounding
Wie in unseren vorherigen Blogbeiträgen beschrieben, können large Language Models (LLMs) wie GPT, Deepseek oder Llama viele Fragen direkt auf Basis der Trainingsdaten beantworten. Dabei besteht jedoch immer die Gefahr von sogenanntem Halluzinieren. Hier liefert das LLM völlig falsche Antworten und Rückschlüsse. Denn man darf nicht vergessen, dass ein LLM nur ein (sehr leistungsstarker) Generator für zufällige (UTF-8) Zeichen ist, der während der eigentlichen Completion keine weitere Recherche durchführt.
Wenn daher echtes Wissen benötigt wird, nutzt man Retrieval Augmented Generation (RAG). Dabei kombiniert man die stärken des Sprachmodells mit einer (Vektor-)Suchmaschine, die den Rechercheteil übernimmt.
Eine allgemeine Einführung in das Thema RAG finden Sie beispielsweise in unserer Dokumentation unter RheinInsights - Documentation - Retrieval Augmented Generation.
Darüber hinaus können bei beim Grounding auch Berechtigungen berücksichtigt werden. Dies beschreiben wir in unserem Blogbeitrag unter RheinInsights - Insights - Sicheres Retrieval Augmented Generation (RAG) mit Berechtigungen.
Elasticsearch und Retrieval Augmented Generation
Um Fragen zu beantworten, kombiniert man daher stets ein LLM mit einer Suchmaschine und dem darin indexierten Wissen. Warum der Ansatz sinnvoll ist, liegt auf der Hand. Nur eine Suchmaschine kann in kürzester Zeit die relevantesten Ergebnisse für eine Suchquery liefern. Eine Suche in einem Quellsystem, in einer Wissensquelle selbst, wäre viel zu langsam und CPU-intesiv.
Und hier kommt Elasticsearch ins Spiel. Elasticsearch ist eine weit verbreitete Suchmaschine. Sie unterstützt Keyword-Suche, Vektorsuche und kann effizient und einfach Filter anwenden. Zudem skalieren Installationen auch bei vielen indexierten Dokumenten sehr gut.
Wie bekommt man die Daten in Elasticsearch?
Wie bei allen RAG- und Enterprise-Search-Anwendungen unterscheidet man zwischen Indexierungs- und Queryzeitpunkt. Nur wenn beide Seiten Hand in Hand gehen, erhalten Sie ein sehr gutes Grounding.
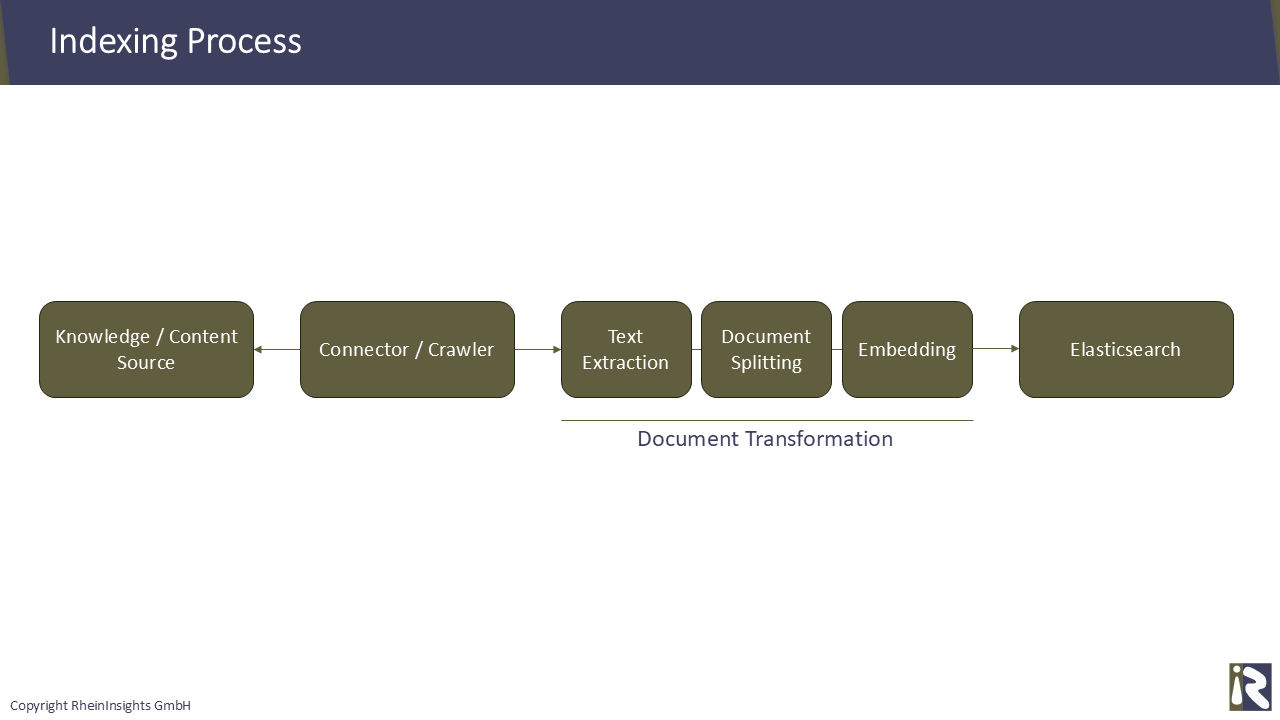
Im Zuge der Indexierung werden daher üblicherweise die folgenden Schritte ausgeführt:
Crawling aller relevanten Daten, beispielsweise aus Confluence-, Github-, SAP SuccessFactors- oder M365.
Textextraktion. Konvertieren der Binär- und HTML-Daten eines jeden Dokuments in Plaintext.
Aufspalten von langen Dokumenten. In diesem Schritt werden sehr lange Dokumente zusätzlich in kleinere Teile aufgeteilt. Der Grund dafür ist, dass extrem lange Dokumente möglicherweise weniger relevante Ergebnisse produzieren, als einzelne Dokumenten-Abschnitte. Beim anschließenden Generierungsschritt stoßen Sie außerdem nicht auf Längenbeschränkungen der Completion-API.
Berechnung von Embeddings. Hier erstellen Sie einen Vektor, den Sie indizieren können. Der Vektor wird üblicherweise ebenfalls mit einem LLM generiert, beispielsweise OpenAIs text-embedding-ada-002 oder mxbai-embed-large. Dieser Vektor wird dann zusammen mit den Textdaten und den von Ihnen bereitgestellten Metadaten indexiert.
Indexierung in Elasticsearch
Interaktion mit der KI - der Suchzeitpunkt
Anschließend kann ein Benutzer mit der KI-Anwendung, beispielsweise einem Bot, interagieren und von ihm sinnvolle Antworten erhalten.
Ein gängiger Ansatz, gerade bei Bots, die mehrere Aufgaben erledigen können, ist der folgende. Die Anwendung stellt fest, dass eine Wissensfrage gestellt wird. Dann fragt sie Elasticsearch entsprechend ab und geniert eine Antwort.
Dazu werden mindestens die folgenden Schritte ausgeführt:
Generieren eines Embeddings für die Anfrage des Benutzers. So erhalten Sie einen Vektor, den Sie für die Vektorsuche verwenden können.
Hierfür müssen Sie natürlich genau dasselbe Embedding-Modell wie in Schritt 4 oben verwenden.
Ist dies nicht der Fall, unterscheiden sich in der Regel die Vektordimensionen. Das bedeutet, dass Sie die Abfrage dann überhaupt nicht ausführen können, da Elasticsearch einen Fehler ausgibt.Anschließend verwendet man die REST-API von Elasticsearch, um die eigentliche Vektorsuche auszuführen.
Generierung. Nun verwendet man die ersten N Suchergebnisse (dies können 10 oder 20 sein) und man lässt das LLM eine Antwort auf die angegebene Benutzeranfrage generieren.
Hier ist auf Seiten immer ein wenig Prompt-Engineering erforderlich, denn man die Treffer zusammen mit der Nutzeranfrage durch das LLM zusammenfassen lassen.
Zudem unterscheiden sich unterschiedliche LLMs doch sehr stark in ihrem Antwortverhalten.
Man kann natürlich auch weitere wichtige Schritte während der Query-Verarbeitung und Ergebnistransformation durchführen. Lesen Sie hier hierzu unseren Blogbeitrag zum Umgang mit mehrsprachigen Eingaben und Suchqueries, RheinInsights - Insights - Übersetzung als Teil unserer Query-Pipeline.
Das Ergebnis des Generierungsschrittes wird dann dem Nutzer zurückgeliefert. Das LLM und weitere Transformationsschritte des Ergebnisses kann die natürlichsprachige Antwort sogar mit Referenzen versehen. Dann der Nutzer die Möglichkeit hat, selbst weiter zu recherchieren.
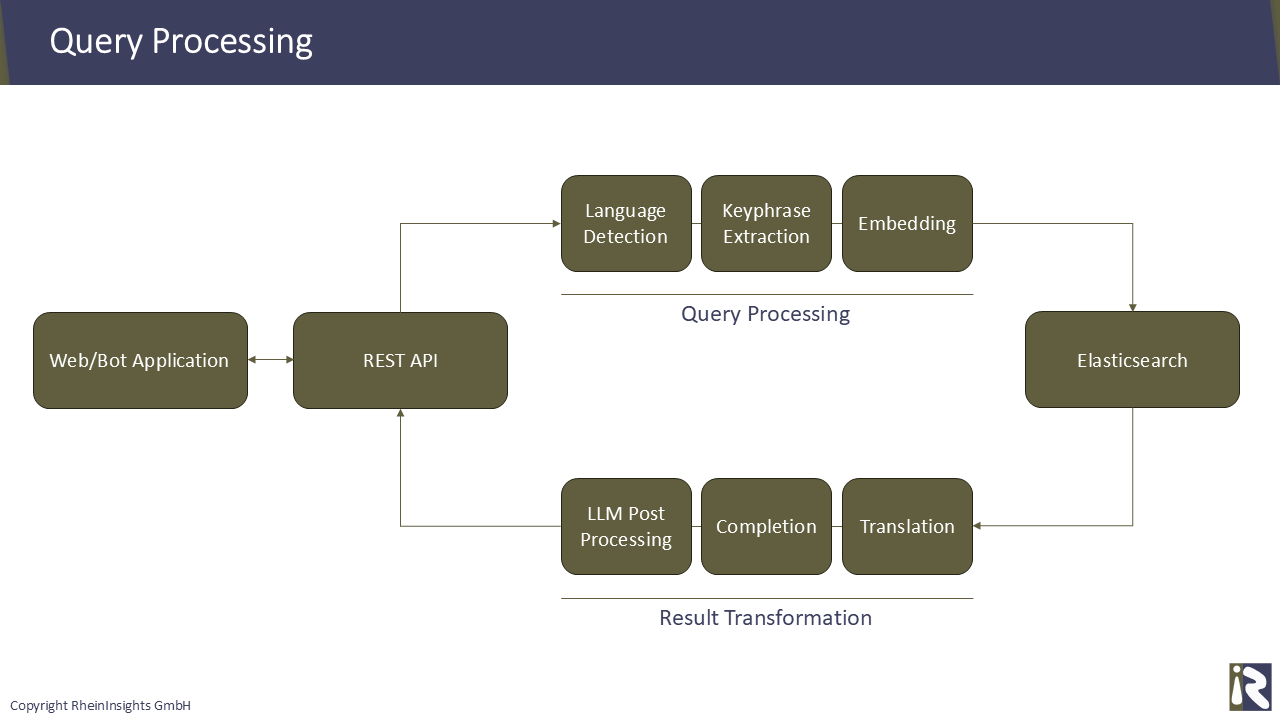
Bitte beachten Sie, dass die alleinige Nutzung der Vektorsuche in Elasticsearch nicht empfehlswert ist. Die Suchergebnisse, gerade bei großen Datenmengen, sind in der Regel nicht immer relevant. Daher nutzen wir immer Hybridsuchen.
Eine Hybridsuche ist eine Kombination aus Keyword-Suche und Vektorsuche. Sie vereint die Vorteile von beiden Ansätzen: Sie generiert stets Suchergebnisse und ist damit weniger streng als eine Keyword-Suche (die auch mal keine Treffer liefert). Die Keyword-Suche stellt jedoch sicher, dass die relevantesten Ergebnisse in der Regel weit vorne sind.
Das Ergebnis
Wenn Sie eine Elasticsearch-Installation im Einsatz haben, dann können Sie diese für Ihre KI-Applikationen zügig nutzen. Denn sowohl die Indexierungsseite als auch die Query-Seite erfordern keine Änderungen an der Elasticsearch-Installation. Sie müssen lediglich einen Suchindex mit einem geeigneten Schema erstellen.
Mit der Hybridsuche erhalten Sie zudem die relevantesten Suchergebnisse. Als Ergebnis haben Sie eine intelligente KI mit Ihrem Unternehmenswissen, welche immer passende und richtige Antworten liefert.
Die RheinInsights Retrieval Suite
Unser Produkt, die RheinInsights Retrieval Suite ist kompatibel mit allen gängigen Suchmaschinen und bietet die oben aufgeführten Komponenten. Wenn Sie unsere Retrieval Suite nutzen können Sie ohne große Umwege, Daten aus Wissensquellen erfassen und in Ihre Bot-Applikation integrieren:
Die Retrieval Suite enthält über 30 Enterprise-Suchkonnektoren, die zuverlässig Wissen indexieren.
Alle Konnektoren unterstützen außerdem das Berechtigungsmodell der Inhaltsquellen. Sprich, Sie können stets eine Secure Search aufbauen und ein berechtigungsbasiertes Grounding nutzen.
Unsere Suite bietet außerdem vorkonfigurierte Indexierungspipelines, die die Daten vor der Indexierung in Elasticsearch verarbeiten.
Unsere Suite stellt außerdem die notwendigen und umfangreiche Query-Pipelines bereit.
Nutzer können Fragen stellen und erhalten hilfreiche Antworten.
Das Grounding erfolgt nur auf dem Wissen, auf das der Nutzer Zugriff hat. Dadurch wird sichergestellt, dass auch in der RAG-Anwendung kein Data-Loss statt findet.
Und unsere Suite unterstützt Deep-Research. Wenn eine schnelle Antwort nicht gut genug ist, wird mehr Kontext errechnet und die Suche verfeinert.