Wie man leicht und sicher Trainingsdaten für Machine Learning im Unternehmen generiert
20. März 2025
Vor Jahren unterstützten wir ein IT-Unternehmen beim Aufbau einer Expertensuche. Das Interessante an dieser Expertensuche war, dass sie nicht auf spärlich gepflegten Profilseiten basierte, sondern auf einem Wissensgraph.
Der Ansatz ist im Wesentlichen folgender: Wir nutzten einen Enterprise Search-Konnektor für Jira, um Beziehungen zwischen Tickets und Interaktionen mit diesen Tickets durch Benutzer aufzubauen. Diese Beziehungen werden dann in einer Tabelle abgelegt und zum Training eines neuronalen Netzwerks, also eines Modells, verwendet.
Das Training lief wie folgt ab: Die Ticketinteraktionen bestehen aus den Ticketbeschreibungen und Titeln, aus denen zunächst Stoppwörter entfernt werden. Aus dem verbleibenden Textbausteinen werden dann dynamisch einige tausend relevante Begriffe isoliert. Sprich, moderne Algorithmen können ein Wörterbuch anhand des Textcorpus dynamisch errechnen. Jeder Begriff wird dann mit den Personen verknüpft, die mit den entsprechenden Tickets interagiert hatten, in denen diese Begriffe auftauchten. Das Resultat ist dann die Eingabe (das Data Set) für das Training des Modells.
Auf Basis solcher Daten erreicht das Modell dann eine sehr hohe Präzision bei der Bestimmung von Experten für gegebene Eingabe-Queries.
Wie können Sie Ihre Daten für das Training spezialisierter Modelle nutzen?
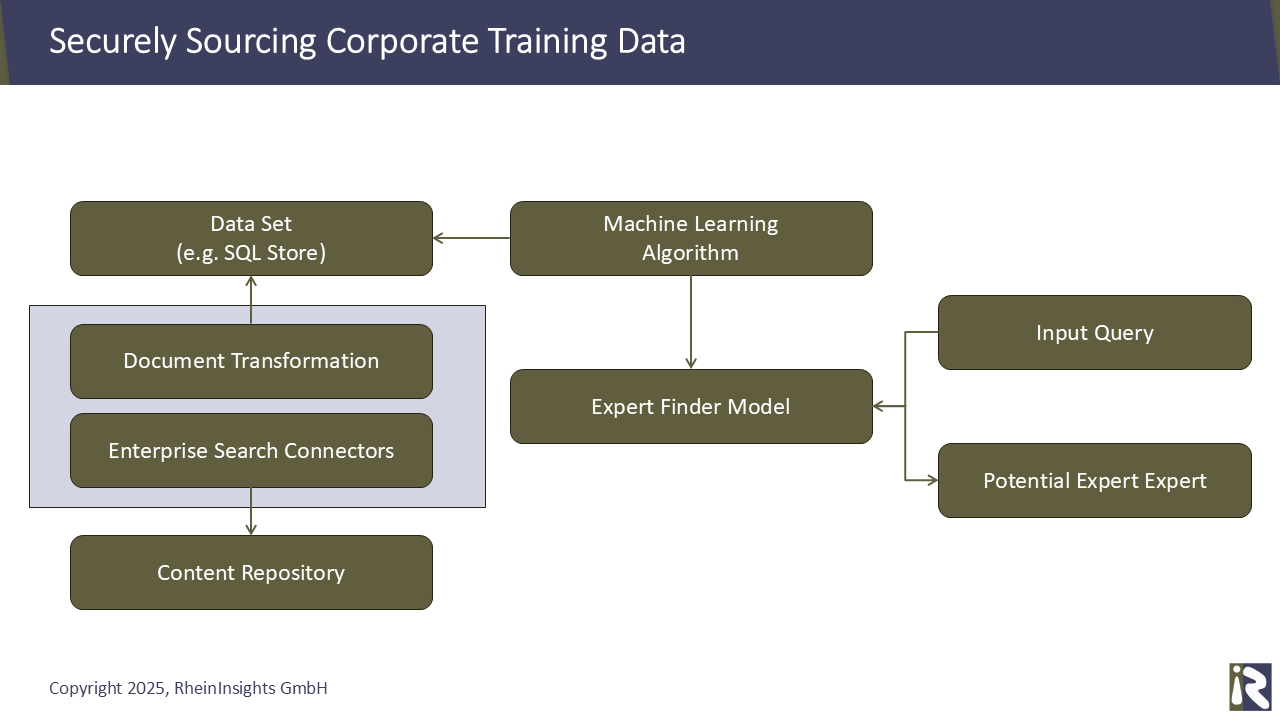
Mithilfe unserer Enterprise-Search-Konnektoren können Daten aus Unternehmenssytemen zuverlässig und gezielt extrahiert und transformiert werden. Diese dienen dann dem Training spezialisierter Modelle.
Der Ansatz ist folgender:
Die Konnektoren der RheinInsights Retrieval Suite extrahieren Dokumente aus den jeweiligen Quellsystemen, zum Beispiel Jira, SharePoint, Notion oder Confluence
. Diese Dokumente können im nächsten Schritt Transformiert werden, siehe https://www.rheininsights.com/de/rheininsights-document-processing-pipelines.php,
Und dann werden diese Dokumente (als Text- vs. Interaktionspaare) beispielsweise in einer SQL-Datenbank gespeichert werden.
Diese Daten können dann als Data Set für das Training verwendet werden.
Das Modell selbst errät dann für eine beliebige Eingabe einen Experten.
Der Ansatz einer Nutzung von Enterprise-Search-Konnektoren hat den Vorteil, dass diese die Trainings-Daten synchron zum Quellsystem halten. So kann das Modell leicht durch Nachtrainieren aktuell gehalten werden.