Ein eigenes Retrieval Augmented Generation Framework - komplett On-Premises
2. April 2025
Es gibt viele Szenarien, in denen die Verarbeitung von Daten in der Cloud nicht zulässig ist. Oft sprechen Unternehmensvorschriften dagegen oder die Daten sind so wichtig, dass Sie nicht außerhalb der eigenen IT-Infrastruktur gespeichert werden sollen. Daher stellt sich immer wieder die Frage, wie lässt sich dennoch das vorhandene Wissen nutzen, um bestmögliche Antworten liefern? Und dies ohne auf die Cloud zurückzugreifen.
Was benötigt man für Retrieval Augmented Generation?
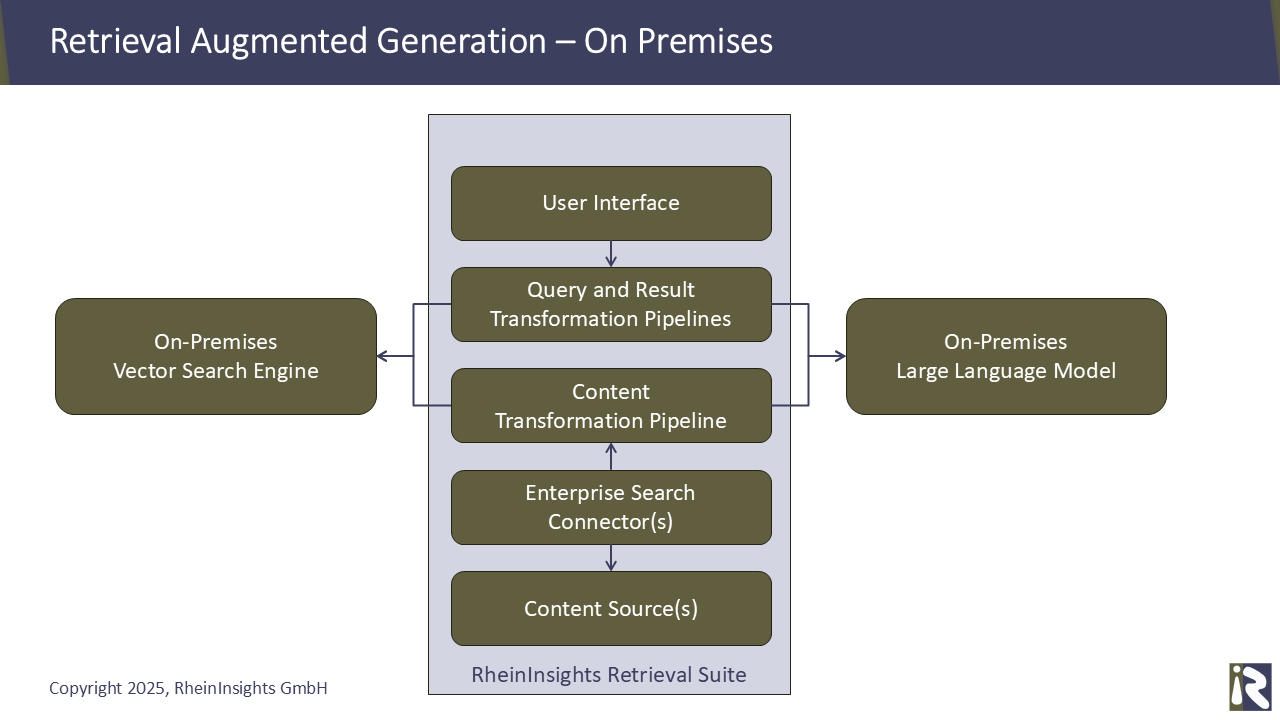
Anwendungen, die Retrieval Augmented Generation (RAG) nutzen, bestehen aus den folgenden Komponenten:
Eine Vektor-Suchmaschine als Herzstück der Anwendung.
Enterprise-Search-Konnektoren, die Daten in die Suchmaschine indexieren.
Zwei Large Language Models (LLMs), also Sprachmodelle. Diese werden benötigt um einerseits Embeddings zu generieren, also um aus Text Vektoren für die Vektorsuche zu errechnen. Andererseits verwendet man ein Modell um Completions (Vervollständigungen) zu errechnen, sprich Antworten und Schlussfolgerungen in natürlicher Sprache zu generieren.
Und man benötigt entweder ein Suchinterface, eine Bot-Integration oder eine ähnliche Integration, damit (authentifizierte) Benutzer mit der RAG-Applikation interagieren können.
Lokales Retrieval Augmented Generation
Wenn man von dem User Interface absieht, müssen im Prinzip nur drei Komponenten aus der Cloud zurück nach On-Premises migriert werden, damit Ihre RAG-Applikation vollständig lokal läuft: die Suchmaschine und die beiden LLMs, also die Sprachmodelle.
On-Premises Suchmaschinen
Skalierbare und hochmoderne Suchmaschinen, die eine Vektorsuche auch on-premises unterstützen, sind beispielsweise Elasticsearch oder Apache Solr. Zudem unterstützen andere Suchmaschinenhersteller on-premises Deployments, zum Beispiel Squirro.
On-Premises Sprachmodelle
Auf der anderen Seite gibt es LLMs kann Ollama on-premises verwendet werden. Voraussetzung ist lediglich eine ausreichend leistungsstarke Hardware. Ist die Hardware nicht stark genug, dann wird die Indexierung, durch das Errechnen der Embeddings, sehr langsam und auch das Errechnen der Completions zum Suchzeitpunkt benötigt dann zu lange.
Konnektoren, Such-Interfaces und Orchestrierung
Darüber hinaus, kann die RheinInsights Retrieval Suite on-premises eingesetzt werden. Diese stellt ein Suchinterface, Konnektoren und auch die Transformations-Pipelines bereit, die für eine RAG-Applikation benötigt wird.
In der Summe, kann man mit diesem Ansatz schnell und einfach eine RAG-Applikationen innerhalb des eigenen Netzwerks aufbauen.
Die RheinInsights Retrieval Suite und Datenschutz
Unsere RheinInsights Retrieval Suite ist die perfekte geeignet für Szenarien, in denen Inhalte on-premises nicht verlassen dürfen. Unsere Suite ist kein Managed Service oder Cloud-Angebot, sondern wird vollständig durch den Kunden betrieben. Auch unser Azure-Angebot läuft als AKS-Lösung in dem Azure des Kunden. Daher haben wir zu keinem Zeitpunkt Zugriff auf die Daten unserer Kunden.