Sourcing Corporate Data Sets for Machine Learning
March 20, 2025
Years ago, we supported an IT company with building an expert search. The interesting part of this expert search was that it was not based on self-managed labels in some user profile store but based on a data interaction graph.
Overall the approach was the following. We used a Jira search connector to build up relationships between tickets and ticket interactions of users. This was stored in a data store and was used for training a neural network, i.e., a model.
The training was done as follows. The ticket interactions where ticket texts which were first processed to remove stop words and out of the remaining result, a few thousand relevant terms were dynamically isolated and computed. This means that there was not a pre-given dictionary, but it was computed based on the text corpus at hand. Each term was combined with persons who interacted with the according tickets, where these terms came up. This was a great data set for actual training.
As a result, the model had a very high precision on determining experts for given topics.
How to Use Your Data for Your Models?
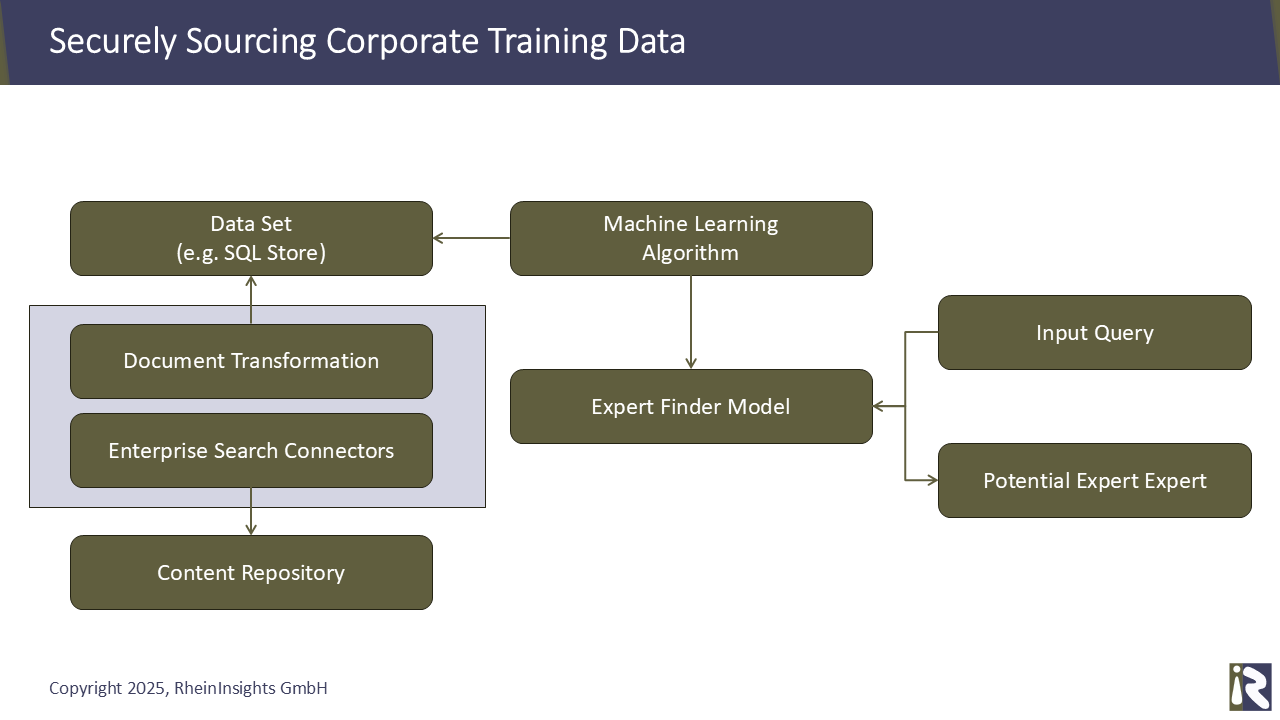
Following this approach, you can use our enterprise search connectors to train your models towards your needs.
The approach is the following.
The connectors of the RheinInsights Retrieval Suite extract documents from your content source(s).
These documents can be further transformed using our document processing pipeline, see https://www.rheininsights.com/en/rheininsights-document-processing-pipelines.php.
Then the resulting data set is stored for instance in a SQL database.
The resulting data set can then be used for training your models.
The benefit with enterprise search connectors is that these reliably keep the data up to date. So you can continuously advance the model with new data coming in.