Documentation
SQL Data Target - Indexing Configuration
The following describes how to configure our connectors to index data into a SQL table as data target.
Technical Prerequisites
Indexing data into SQL tables follows the same permissions at JDBC and SQL Server Connector . This means that the connector must be able to connect and to authenticate against the server. The connector also must be able to create a new table, if needed, as well as to write data into these tables, to read data and to delete rows.
Connector Configuration
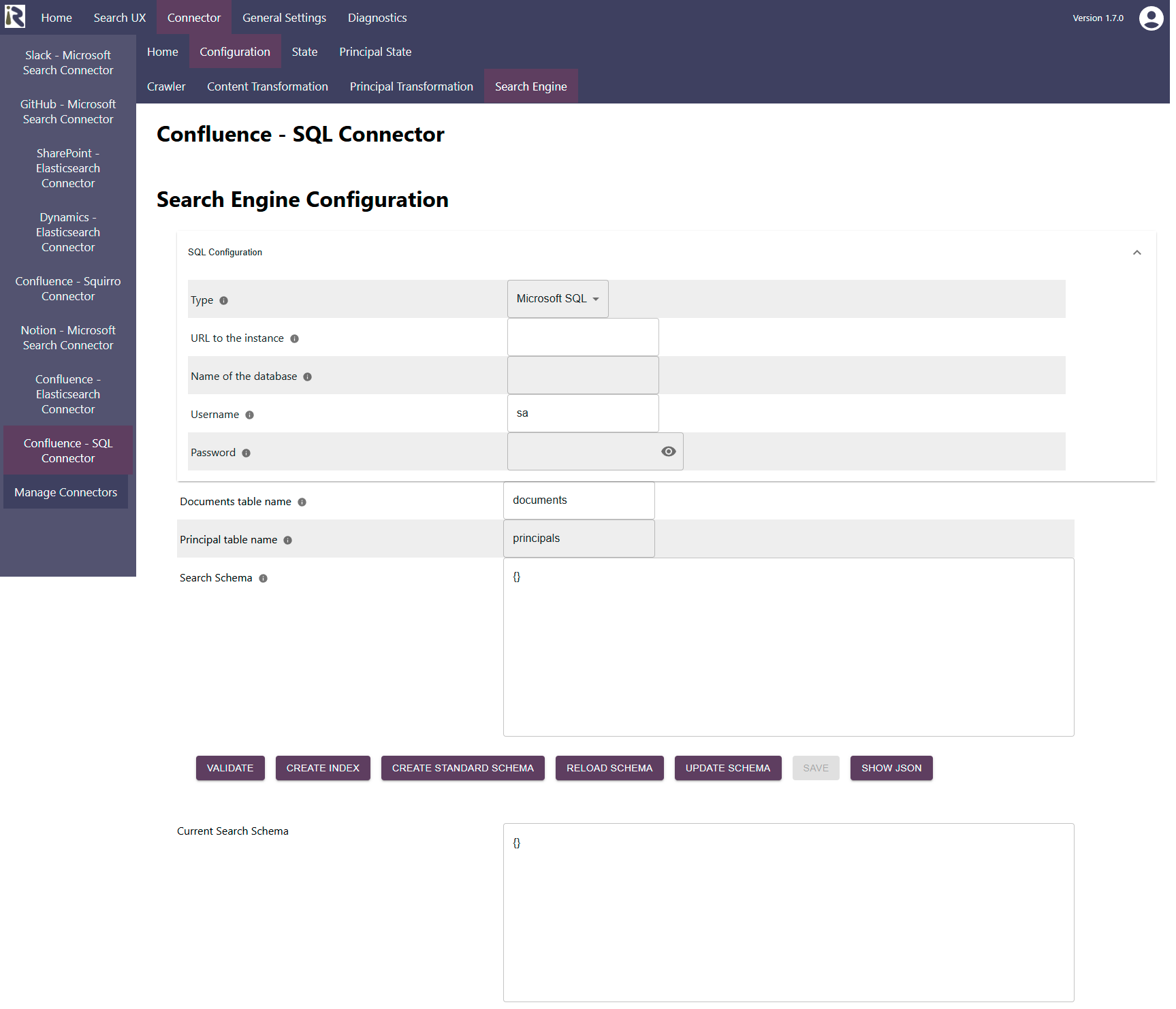
Database type: please choose which kind of database you like to crawl.
Url to the server: Please add the server url, port and database name of the server, you like to crawl.
For Postgres instances this is “<FQDN>:<Port>/<database>”
For Microsoft SQL this is <FQDN of the instance>:<port>. Please add
Username: is the user name which is used by the connector to crawl the instance. Please see the above for the necessary user permissions.
Password: is the corresponding password for the crawl user
Documents table name. Determines the table name where the documents will be synchronized to
Principal table name. Determines the table name where the user-group relationships will be synchronized to
When finished with setting these fields, click on validate and save. If you observe any issues, then the validator will let you know or you can find more insights in the log files.
Please note that maintaining the index schema from this dialog is not supported.