Documentation
- Getting Started
- Deployment

- Technical Prerequisites
- Data Privacy and Routing
- Administration
- Enterprise Search Connectors
- Managing Connectors
- Connector Home View
- Sources
- Content Transformation
- ACL Assigner
- Adjustable Text Extractor
- Data Logger
- Document Classifier
- Document Preview Generation
- Document Splitter
- Document Translation
- Html Token Remover
- Metadata Assigner
- Metadata Extractor
- Metadata Mapper
- Text Extractor
- Vectorizer and Embeddings
- LLM Specific Configurations - Content Transformers
- Security Transformation
- General Crawl Settings
- Performance Considerations
- Crawl Modes
- Crawl Scheduling
- Standard Schema
- State View
- Principal State View
- Search Experiences
- AI and Query Pipelines
- Search Engines
- MCP, Agents and Bot Integrations
- Backup and Restore Concept
- Software Updates and Upgrade
- Releases and Release Notes
Adjustable Text Extractor
With this stage, you can flexibly extract text from your body contents. It works on plain text or HTML. This means that a text extraction is advised before applying this stage.
The stage accepts a regular expression to narrow down the text which should be extracted and separate it from text which should remain as is. This text portion can be further processed either via regular expressions or by interpreting it as a specific JSON format (a multivalued dictionary).
Example
As an example, the following text (Confluence’s card macro) can be easily transformed this way.
Prefix
<ac:structured-macro ac:name=\"aura-cards\"><!-- ...-->
<ac:parameter ac:name=\"cardsCollection\">
[{"title":"card1",
"body":"body1",
"color":"#000000",
"icon":"faChild"}]
</ac:parameter>
</ac:structured-macro>
<!--...-->
Suffix
Can be transformed to
Prefix title card1 body body1 Suffix
This stage always acts on the document body. If you like to transform document metadata, then please use Metadata Extractor .
Configuration Parameters
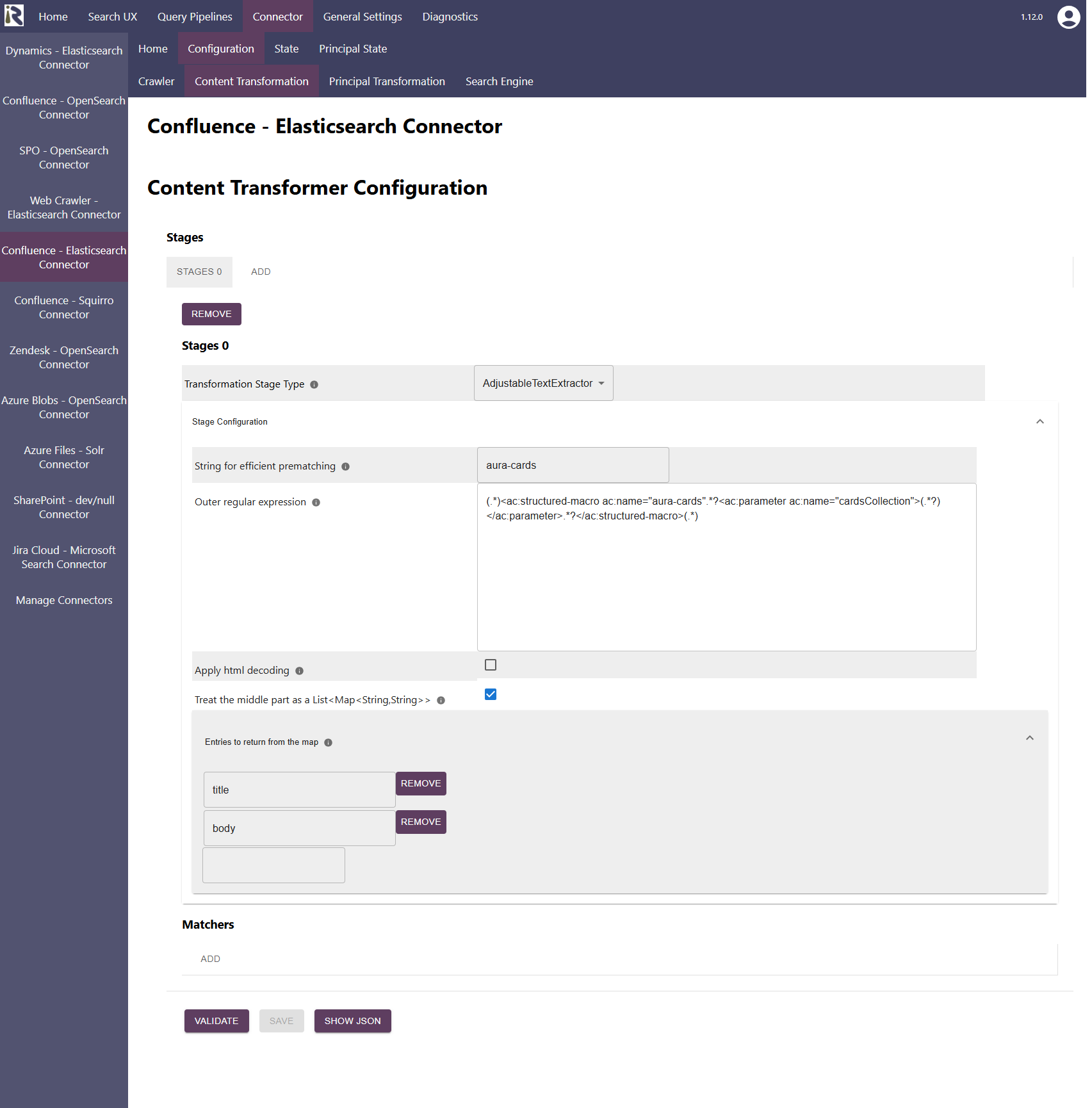
Transformation Stage Type must be set to AdjustableTextExtractor
String for efficient prematching: This value can be left empty. If given it is used to avoid a costly regular expression matching if the string is not contained in the document body.
Outer regular expression. This is a Java regular expression and it must contain three matching groups, i.e., braces. The first one is used to determine a prefix, the third to determine the suffix (see example above). The middle part is used to detect the part which will be further processed.
Apply html decoding. This applies an HTML decode on the second capture group of 3. It is needed, in examples, as the one shown example above. There, the JSON is HTML encoded and must be decoded before processing.Treat the middle part as a List<Map<String,String>>. If this is set to true, the result of matching group will be treated as a JSON map, as in the example above.
Entries to return from the map. If you decide to use this step to extract a List<Map<String,String>>, then you can define which fields you like to include in the document body. If this list is empty, then all fields are added to the body.
Inner regular expression. If you set “treat the middle part as a List<Map<String,String>>” to false, then you can specify a regular expression to return capture groups from a regular expression. This regex is applied to the second capture group of the one defined in 3.
Pro tip: You can use the Data Logger stage to first see how the content looks like. Afterwards, you can configure this stage more precisely.