Smart PMOs for Large Organizations
April 28, 2025
In this blog post, we will outline how retrieval augmented generation (RAG) supports the staffing step during a project initialization. We outline how project member roles will be matched to available staff members.
Overview
All organizations need to run projects in order to adopt to new strategical needs. For instance to introduce new software, build new plants, change infrastructure or to define and introduce new processes. The difference to line operations is that such projects have a clear starting point and a planned time of ending. Therefore new projects come with the need to staff the right project team during the so-called project initialization phase.
Project Staffing
After the project has been defined and the decision was made to schedule it, staffing needs to take place. We assume that the project roles are clear and also the associated profiles are known.
Obviously, in this step one needs to find persons who have the right skills and who are available for the project at hand – when they are needed. Normally, internal teams such as the project management office (PMO) or recruiting do this kind of sourcing.
In larger organizations, there is also an overview of the staffing of other projects. For the new project, the PMO thus can tell who is when available for a new project, based on the project schedules they have.
But are these persons the right ones for the roles in the new project? To make sure that the profile matches, there must be an alignment of the project role’s profile and the CV or skills of the candidates. If these match, then they are proposed for the new project.
Automation of the Matching Process
The process of manually scrolling through potentially hundreds of CVs is however very time consuming. Here, Retrieval Augmented Generation comes into place.
Indexing CVs and Team Availability Into a Vector Search
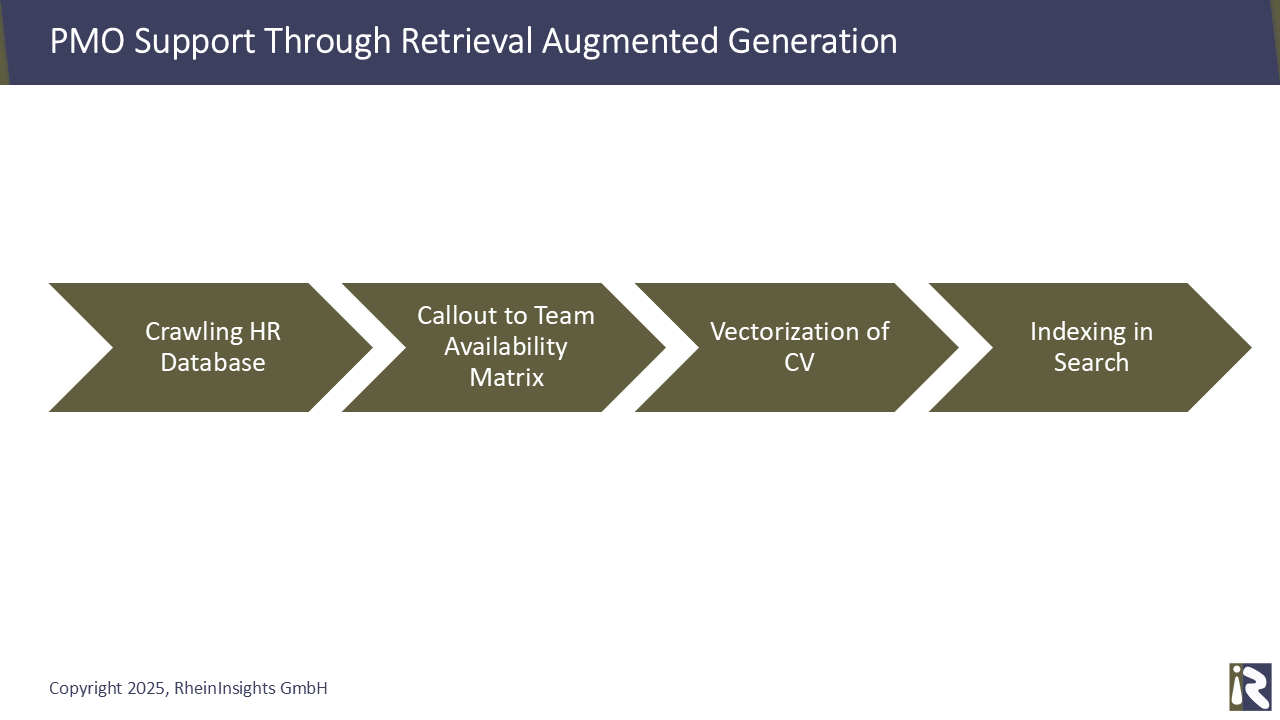
What we do is to index all staff profiles into a vector search engine, such as Azure AI Search, Elasticsearch, Apache Solr or similar. We do this along with the team availability information based on the PMO’s project schedules.
Index Schema
This can be done for instance with the following index schema
body, this will contain the CV as plain text
vectorBody, which will be an N-dimensional vector
availability, which will be an array of objects. Where each entry contains an object with the fields “from” and “to”
Indexing
One can e.g. use a file share connector, a SharePoint or SAP SuccessFactors connector, to now index the CVs and availability. The choice of connector depends on where the CVs are located. This connector normally runs once or twice a day to reindex the availabilities or updates in the CVs.
Before providing the CV to the search index, the content processing pipeline must execute at least two steps:
a custom processing stage. This fetches the team availability from the PMO’s schedule database or Excel.
an embedding stage. This uses standard embedding to vectorize the CV. This information will finally be indexed.
As a result, you now have the CVs and availabilities in the search index.
Supporting the Staffing Process
To identify staff members who are available to fill a project role, we implement the following.
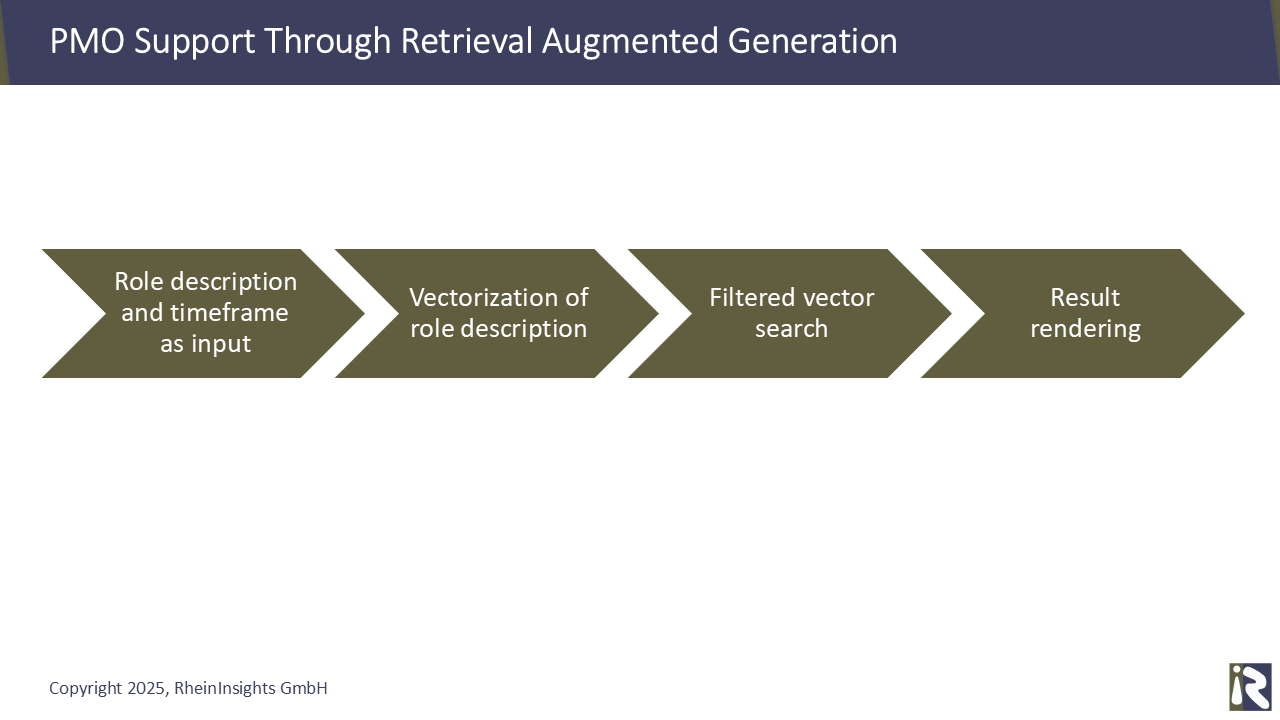
For a given project opportunity, we leverage the search index as follows.
In the first step, we vectorize the role profile and using the same embedding as we use during indexing.
Then we execute a filtered query against the search index, i.e., a nearest neighbor search for the vector in combination with a filter on the team member’s availabilities.
The result are all persons who match the role description and who are available during the time frame where they are needed for the project.